mirror of
https://github.com/loro-dev/loro.git
synced 2025-02-05 20:17:13 +00:00
Merge branch 'main' of https://github.com/loro-dev/loro
This commit is contained in:
commit
b6a4a1ed78
27 changed files with 1935 additions and 86 deletions
|
|
@ -16,7 +16,13 @@ moveit = "0.5.0"
|
|||
pin-project = "1.0.10"
|
||||
serde = {version = "1.0.140", features = ["derive"]}
|
||||
thiserror = "1.0.31"
|
||||
im = "15.1.0"
|
||||
|
||||
[dev-dependencies]
|
||||
proptest = "1.0.0"
|
||||
proptest-derive = "0.3.0"
|
||||
rand = "0.8.5"
|
||||
|
||||
# See https://matklad.github.io/2021/02/27/delete-cargo-integration-tests.html
|
||||
[lib]
|
||||
doctest = false
|
||||
|
|
|
|||
18
crates/loro-core/justfile
Normal file
18
crates/loro-core/justfile
Normal file
|
|
@ -0,0 +1,18 @@
|
|||
build:
|
||||
cargo build
|
||||
|
||||
test:
|
||||
cargo nextest run
|
||||
|
||||
# test without proptest
|
||||
test-fast:
|
||||
RUSTFLAGS='--cfg no_proptest' cargo nextest run
|
||||
|
||||
check-unsafe:
|
||||
env RUSTFLAGS="-Funsafe-code --cap-lints=warn" cargo check
|
||||
|
||||
deny:
|
||||
cargo deny check
|
||||
|
||||
crev:
|
||||
cargo crev crate check
|
||||
|
|
@ -1,3 +1,9 @@
|
|||
//! [Change]s are merged ops.
|
||||
//!
|
||||
//! Every [Change] has deps on other [Change]s. All [Change]s in the document thus form a DAG.
|
||||
//! Note, `dep` may point to the middle of the other [Change].
|
||||
//!
|
||||
//! In future, we may also use [Change] to represent a transaction. But this decision is postponed.
|
||||
use std::char::MAX;
|
||||
|
||||
use crate::{
|
||||
|
|
@ -97,7 +103,7 @@ impl Mergable<ChangeMergeCfg> for Change {
|
|||
}
|
||||
|
||||
if other.deps.is_empty()
|
||||
|| (other.deps.len() == 1 && self.id.is_connected_id(&other.deps[0], self.len() as u32))
|
||||
|| (other.deps.len() == 1 && self.id.is_connected_id(&other.deps[0], self.len()))
|
||||
{
|
||||
return false;
|
||||
}
|
||||
|
|
@ -111,7 +117,7 @@ impl Mergable<ChangeMergeCfg> for Change {
|
|||
}
|
||||
|
||||
self.id.client_id == other.id.client_id
|
||||
&& self.id.counter + self.len() as u32 == other.id.counter
|
||||
&& self.id.counter + self.len() as Counter == other.id.counter
|
||||
&& self.lamport + self.len() as Lamport == other.lamport
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -70,6 +70,15 @@ impl MapContainer {
|
|||
},
|
||||
}]);
|
||||
|
||||
if self.value.is_some() {
|
||||
self.value
|
||||
.as_mut()
|
||||
.unwrap()
|
||||
.as_map_mut()
|
||||
.unwrap()
|
||||
.insert(key.clone(), value.clone().into());
|
||||
}
|
||||
|
||||
self.state.insert(
|
||||
key,
|
||||
ValueSlot {
|
||||
|
|
@ -120,6 +129,15 @@ impl Container for MapContainer {
|
|||
counter: op.id().counter,
|
||||
},
|
||||
);
|
||||
|
||||
if self.value.is_some() {
|
||||
self.value
|
||||
.as_mut()
|
||||
.unwrap()
|
||||
.as_map_mut()
|
||||
.unwrap()
|
||||
.insert(v.key.clone(), v.value.clone().into());
|
||||
}
|
||||
}
|
||||
}
|
||||
_ => unreachable!(),
|
||||
|
|
|
|||
|
|
@ -48,7 +48,7 @@ mod map_proptest {
|
|||
map.insert(k.clone(), v.clone());
|
||||
container.insert(k.clone().into(), v.clone());
|
||||
let snapshot = container.get_value();
|
||||
for (key, value) in snapshot.to_map().unwrap().iter() {
|
||||
for (key, value) in snapshot.as_map().unwrap().iter() {
|
||||
assert_eq!(map.get(&key.to_string()).map(|x|x.clone().into()), Some(value.clone()));
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1,4 +1,4 @@
|
|||
use crate::{ContentType, InsertContent, ID};
|
||||
use crate::{id::Counter, ContentType, InsertContent, ID};
|
||||
use rle::{HasLength, Mergable, Sliceable};
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
|
|
@ -12,9 +12,9 @@ pub struct TextContent {
|
|||
impl Mergable for TextContent {
|
||||
fn is_mergable(&self, other: &Self, _: &()) -> bool {
|
||||
other.id.client_id == self.id.client_id
|
||||
&& self.id.counter + self.len() as u32 == other.id.counter
|
||||
&& self.id.counter + self.len() as Counter == other.id.counter
|
||||
&& self.id.client_id == other.origin_left.client_id
|
||||
&& self.id.counter + self.len() as u32 - 1 == other.origin_left.counter
|
||||
&& self.id.counter + self.len() as Counter - 1 == other.origin_left.counter
|
||||
&& self.origin_right == other.origin_right
|
||||
}
|
||||
|
||||
|
|
@ -36,12 +36,12 @@ impl Sliceable for TextContent {
|
|||
TextContent {
|
||||
origin_left: ID {
|
||||
client_id: self.id.client_id,
|
||||
counter: self.id.counter + from as u32 - 1,
|
||||
counter: self.id.counter + from as Counter - 1,
|
||||
},
|
||||
origin_right: self.origin_right,
|
||||
id: ID {
|
||||
client_id: self.id.client_id,
|
||||
counter: self.id.counter + from as u32,
|
||||
counter: self.id.counter + from as Counter,
|
||||
},
|
||||
text: self.text[from..to].to_owned(),
|
||||
}
|
||||
|
|
|
|||
|
|
@ -0,0 +1,421 @@
|
|||
//! DAG (Directed Acyclic Graph) is a common data structure in distributed system.
|
||||
//!
|
||||
//! This mod contains the DAGs in our CRDT. It's not a general DAG, it has some specific properties that
|
||||
//! we used to optimize the speed:
|
||||
//! - Each node has lamport clock.
|
||||
//! - Each node has its ID (client_id, counter).
|
||||
//! - We use ID to refer to node rather than content addressing (hash)
|
||||
//!
|
||||
use std::{
|
||||
collections::{BinaryHeap, HashMap, HashSet, VecDeque},
|
||||
ops::Range,
|
||||
};
|
||||
|
||||
use fxhash::{FxHashMap, FxHashSet};
|
||||
mod iter;
|
||||
mod mermaid;
|
||||
#[cfg(test)]
|
||||
mod test;
|
||||
|
||||
use crate::{
|
||||
change::Lamport,
|
||||
id::{ClientID, Counter, ID},
|
||||
span::{CounterSpan, IdSpan},
|
||||
version::VersionVector,
|
||||
};
|
||||
|
||||
use self::{
|
||||
iter::{iter_dag, iter_dag_with_vv, DagIterator, DagIteratorVV},
|
||||
mermaid::dag_to_mermaid,
|
||||
};
|
||||
|
||||
pub(crate) trait DagNode {
|
||||
fn id_start(&self) -> ID;
|
||||
fn lamport_start(&self) -> Lamport;
|
||||
fn len(&self) -> usize;
|
||||
fn deps(&self) -> &Vec<ID>;
|
||||
|
||||
#[inline]
|
||||
fn is_empty(&self) -> bool {
|
||||
self.len() == 0
|
||||
}
|
||||
|
||||
#[inline]
|
||||
fn id_span(&self) -> IdSpan {
|
||||
let id = self.id_start();
|
||||
IdSpan {
|
||||
client_id: id.client_id,
|
||||
counter: CounterSpan::new(id.counter, id.counter + self.len() as Counter),
|
||||
}
|
||||
}
|
||||
|
||||
/// inclusive end
|
||||
#[inline]
|
||||
fn id_end(&self) -> ID {
|
||||
let id = self.id_start();
|
||||
ID {
|
||||
client_id: id.client_id,
|
||||
counter: id.counter + self.len() as Counter - 1,
|
||||
}
|
||||
}
|
||||
|
||||
#[inline]
|
||||
fn get_lamport_from_counter(&self, c: Counter) -> Lamport {
|
||||
self.lamport_start() + c as Lamport - self.id_start().counter as Lamport
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone, PartialEq, Eq)]
|
||||
pub(crate) struct Path {
|
||||
retreat: Vec<IdSpan>,
|
||||
forward: Vec<IdSpan>,
|
||||
}
|
||||
|
||||
#[allow(clippy::ptr_arg)]
|
||||
fn reverse_path(path: &mut Vec<IdSpan>) {
|
||||
path.reverse();
|
||||
for span in path.iter_mut() {
|
||||
span.counter.reverse();
|
||||
}
|
||||
}
|
||||
|
||||
/// Dag (Directed Acyclic Graph).
|
||||
///
|
||||
/// We have following invariance in DAG
|
||||
/// - All deps' lamports are smaller than current node's lamport
|
||||
pub(crate) trait Dag {
|
||||
type Node: DagNode;
|
||||
|
||||
fn get(&self, id: ID) -> Option<&Self::Node>;
|
||||
|
||||
#[inline]
|
||||
fn contains(&self, id: ID) -> bool {
|
||||
self.vv().includes(id)
|
||||
}
|
||||
|
||||
fn frontier(&self) -> &[ID];
|
||||
fn roots(&self) -> Vec<&Self::Node>;
|
||||
fn vv(&self) -> VersionVector;
|
||||
|
||||
//
|
||||
// TODO: Maybe use Result return type
|
||||
// TODO: Maybe we only need one heap?
|
||||
// TODO: benchmark
|
||||
// how to test better?
|
||||
// - converge through other nodes
|
||||
//
|
||||
/// only returns a single root.
|
||||
/// but the least common ancestor may be more than one root.
|
||||
/// But that is a rare case.
|
||||
///
|
||||
#[inline]
|
||||
fn find_common_ancestor(&self, a_id: ID, b_id: ID) -> Option<ID> {
|
||||
find_common_ancestor(
|
||||
&|id| self.get(id).map(|x| x as &dyn DagNode),
|
||||
a_id,
|
||||
b_id,
|
||||
|_, _, _| {},
|
||||
)
|
||||
}
|
||||
|
||||
/// TODO: we probably need cache to speedup this
|
||||
#[inline]
|
||||
fn get_vv(&self, id: ID) -> VersionVector {
|
||||
get_version_vector(&|id| self.get(id).map(|x| x as &dyn DagNode), id)
|
||||
}
|
||||
|
||||
#[inline]
|
||||
fn find_path(&self, from: ID, to: ID) -> Option<Path> {
|
||||
let mut ans: Option<Path> = None;
|
||||
|
||||
fn get_rev_path(target: ID, from: ID, to_from_map: &FxHashMap<ID, ID>) -> Vec<IdSpan> {
|
||||
let mut last_visited: Option<ID> = None;
|
||||
let mut a_rev_path = vec![];
|
||||
let mut node_id = target;
|
||||
node_id = *to_from_map.get(&node_id).unwrap();
|
||||
loop {
|
||||
if let Some(last_id) = last_visited {
|
||||
if last_id.client_id == node_id.client_id {
|
||||
debug_assert!(last_id.counter < node_id.counter);
|
||||
a_rev_path.push(IdSpan {
|
||||
client_id: last_id.client_id,
|
||||
counter: CounterSpan::new(last_id.counter, node_id.counter + 1),
|
||||
});
|
||||
last_visited = None;
|
||||
} else {
|
||||
a_rev_path.push(IdSpan {
|
||||
client_id: last_id.client_id,
|
||||
counter: CounterSpan::new(last_id.counter, last_id.counter + 1),
|
||||
});
|
||||
last_visited = Some(node_id);
|
||||
}
|
||||
} else {
|
||||
last_visited = Some(node_id);
|
||||
}
|
||||
|
||||
if node_id == from {
|
||||
break;
|
||||
}
|
||||
|
||||
node_id = *to_from_map.get(&node_id).unwrap();
|
||||
}
|
||||
|
||||
if let Some(last_id) = last_visited {
|
||||
a_rev_path.push(IdSpan {
|
||||
client_id: last_id.client_id,
|
||||
counter: CounterSpan::new(last_id.counter, last_id.counter + 1),
|
||||
});
|
||||
}
|
||||
|
||||
a_rev_path
|
||||
}
|
||||
|
||||
find_common_ancestor(
|
||||
&|id| self.get(id).map(|x| x as &dyn DagNode),
|
||||
from,
|
||||
to,
|
||||
|ancestor, a_path, b_path| {
|
||||
let mut a_path = get_rev_path(ancestor, from, a_path);
|
||||
let b_path = get_rev_path(ancestor, to, b_path);
|
||||
reverse_path(&mut a_path);
|
||||
ans = Some(Path {
|
||||
retreat: a_path,
|
||||
forward: b_path,
|
||||
});
|
||||
},
|
||||
);
|
||||
|
||||
ans
|
||||
}
|
||||
|
||||
fn iter_with_vv(&self) -> DagIteratorVV<'_, Self::Node>
|
||||
where
|
||||
Self: Sized,
|
||||
{
|
||||
iter_dag_with_vv(self)
|
||||
}
|
||||
|
||||
fn iter(&self) -> DagIterator<'_, Self::Node>
|
||||
where
|
||||
Self: Sized,
|
||||
{
|
||||
iter_dag(self)
|
||||
}
|
||||
|
||||
/// You can visualize and generate img link at https://mermaid.live/
|
||||
#[inline]
|
||||
fn mermaid(&self) -> String
|
||||
where
|
||||
Self: Sized,
|
||||
{
|
||||
dag_to_mermaid(self)
|
||||
}
|
||||
}
|
||||
|
||||
fn get_version_vector<'a, Get>(get: &'a Get, id: ID) -> VersionVector
|
||||
where
|
||||
Get: Fn(ID) -> Option<&'a dyn DagNode>,
|
||||
{
|
||||
let mut vv = VersionVector::new();
|
||||
let mut visited: FxHashSet<ID> = FxHashSet::default();
|
||||
vv.insert(id.client_id, id.counter + 1);
|
||||
let node = get(id).unwrap();
|
||||
|
||||
if node.deps().is_empty() {
|
||||
return vv;
|
||||
}
|
||||
|
||||
let mut stack = Vec::new();
|
||||
for dep in node.deps() {
|
||||
stack.push(dep);
|
||||
}
|
||||
|
||||
while !stack.is_empty() {
|
||||
let node_id = *stack.pop().unwrap();
|
||||
let node = get(node_id).unwrap();
|
||||
let node_id_start = node.id_start();
|
||||
if !visited.contains(&node_id_start) {
|
||||
vv.try_update_end(node_id);
|
||||
for dep in node.deps() {
|
||||
if !visited.contains(dep) {
|
||||
stack.push(dep);
|
||||
}
|
||||
}
|
||||
|
||||
visited.insert(node_id_start);
|
||||
}
|
||||
}
|
||||
|
||||
vv
|
||||
}
|
||||
|
||||
// fn mermaid<T>(dag: &impl Dag<Node = T>) -> String {
|
||||
// dag
|
||||
// }
|
||||
|
||||
fn find_common_ancestor<'a, F, G>(get: &'a F, a_id: ID, b_id: ID, mut on_found: G) -> Option<ID>
|
||||
where
|
||||
F: Fn(ID) -> Option<&'a dyn DagNode>,
|
||||
G: FnMut(ID, &FxHashMap<ID, ID>, &FxHashMap<ID, ID>),
|
||||
{
|
||||
if a_id.client_id == b_id.client_id {
|
||||
if a_id.counter <= b_id.counter {
|
||||
Some(a_id)
|
||||
} else {
|
||||
Some(b_id)
|
||||
}
|
||||
} else {
|
||||
#[derive(Debug, PartialEq, Eq)]
|
||||
struct OrdId<'a> {
|
||||
id: ID,
|
||||
lamport: Lamport,
|
||||
deps: &'a [ID],
|
||||
}
|
||||
|
||||
impl<'a> PartialOrd for OrdId<'a> {
|
||||
fn partial_cmp(&self, other: &Self) -> Option<std::cmp::Ordering> {
|
||||
Some(self.lamport.cmp(&other.lamport))
|
||||
}
|
||||
}
|
||||
|
||||
impl<'a> Ord for OrdId<'a> {
|
||||
fn cmp(&self, other: &Self) -> std::cmp::Ordering {
|
||||
self.lamport.cmp(&other.lamport)
|
||||
}
|
||||
}
|
||||
|
||||
let mut _a_vv: HashMap<ClientID, Counter, _> = FxHashMap::default();
|
||||
let mut _b_vv: HashMap<ClientID, Counter, _> = FxHashMap::default();
|
||||
// Invariant: every op id inserted to the a_heap is a key in a_path map, except for a_id
|
||||
let mut _a_heap: BinaryHeap<OrdId> = BinaryHeap::new();
|
||||
// Likewise
|
||||
let mut _b_heap: BinaryHeap<OrdId> = BinaryHeap::new();
|
||||
// FxHashMap<To, From> is used to track the deps path of each node
|
||||
let mut _a_path: FxHashMap<ID, ID> = FxHashMap::default();
|
||||
let mut _b_path: FxHashMap<ID, ID> = FxHashMap::default();
|
||||
{
|
||||
let a = get(a_id).unwrap();
|
||||
let b = get(b_id).unwrap();
|
||||
_a_heap.push(OrdId {
|
||||
id: a_id,
|
||||
lamport: a.get_lamport_from_counter(a_id.counter),
|
||||
deps: a.deps(),
|
||||
});
|
||||
_b_heap.push(OrdId {
|
||||
id: b_id,
|
||||
lamport: b.get_lamport_from_counter(b_id.counter),
|
||||
deps: b.deps(),
|
||||
});
|
||||
_a_vv.insert(a_id.client_id, a_id.counter + 1);
|
||||
_b_vv.insert(b_id.client_id, b_id.counter + 1);
|
||||
}
|
||||
|
||||
while !_a_heap.is_empty() || !_b_heap.is_empty() {
|
||||
let (a_heap, b_heap, a_vv, b_vv, a_path, b_path, _swapped) = if _a_heap.is_empty()
|
||||
|| (_a_heap.peek().map(|x| x.lamport).unwrap_or(0)
|
||||
< _b_heap.peek().map(|x| x.lamport).unwrap_or(0))
|
||||
{
|
||||
// swap
|
||||
(
|
||||
&mut _b_heap,
|
||||
&mut _a_heap,
|
||||
&mut _b_vv,
|
||||
&mut _a_vv,
|
||||
&mut _b_path,
|
||||
&mut _a_path,
|
||||
true,
|
||||
)
|
||||
} else {
|
||||
(
|
||||
&mut _a_heap,
|
||||
&mut _b_heap,
|
||||
&mut _a_vv,
|
||||
&mut _b_vv,
|
||||
&mut _a_path,
|
||||
&mut _b_path,
|
||||
false,
|
||||
)
|
||||
};
|
||||
|
||||
while !a_heap.is_empty()
|
||||
&& a_heap.peek().map(|x| x.lamport).unwrap_or(0)
|
||||
>= b_heap.peek().map(|x| x.lamport).unwrap_or(0)
|
||||
{
|
||||
let a = a_heap.pop().unwrap();
|
||||
let id = a.id;
|
||||
if let Some(counter_end) = b_vv.get(&id.client_id) {
|
||||
if id.counter < *counter_end {
|
||||
b_path
|
||||
.entry(id)
|
||||
.or_insert_with(|| ID::new(id.client_id, counter_end - 1));
|
||||
|
||||
on_found(id, &_a_path, &_b_path);
|
||||
return Some(id);
|
||||
}
|
||||
}
|
||||
|
||||
// if swapped {
|
||||
// println!("A");
|
||||
// } else {
|
||||
// println!("B");
|
||||
// }
|
||||
// dbg!(&a);
|
||||
|
||||
#[cfg(debug_assertions)]
|
||||
{
|
||||
if let Some(v) = a_vv.get(&a.id.client_id) {
|
||||
assert!(*v > a.id.counter)
|
||||
}
|
||||
}
|
||||
|
||||
for dep_id in a.deps {
|
||||
if a_path.contains_key(dep_id) {
|
||||
continue;
|
||||
}
|
||||
|
||||
let dep = get(*dep_id).unwrap();
|
||||
a_heap.push(OrdId {
|
||||
id: *dep_id,
|
||||
lamport: dep.get_lamport_from_counter(dep_id.counter),
|
||||
deps: dep.deps(),
|
||||
});
|
||||
a_path.insert(*dep_id, a.id);
|
||||
if dep.id_start() != *dep_id {
|
||||
a_path.insert(dep.id_start(), *dep_id);
|
||||
}
|
||||
|
||||
if let Some(v) = a_vv.get_mut(&dep_id.client_id) {
|
||||
if *v < dep_id.counter + 1 {
|
||||
*v = dep_id.counter + 1;
|
||||
}
|
||||
} else {
|
||||
a_vv.insert(dep_id.client_id, dep_id.counter + 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
None
|
||||
}
|
||||
}
|
||||
|
||||
fn update_frontier(frontier: &mut Vec<ID>, new_node_id: ID, new_node_deps: &[ID]) {
|
||||
frontier.retain(|x| {
|
||||
if x.client_id == new_node_id.client_id && x.counter <= new_node_id.counter {
|
||||
return false;
|
||||
}
|
||||
|
||||
!new_node_deps
|
||||
.iter()
|
||||
.any(|y| y.client_id == x.client_id && y.counter >= x.counter)
|
||||
});
|
||||
|
||||
// nodes from the same client with `counter < new_node_id.counter`
|
||||
// are filtered out from frontier.
|
||||
if frontier
|
||||
.iter()
|
||||
.all(|x| x.client_id != new_node_id.client_id)
|
||||
{
|
||||
frontier.push(new_node_id);
|
||||
}
|
||||
}
|
||||
175
crates/loro-core/src/dag/iter.rs
Normal file
175
crates/loro-core/src/dag/iter.rs
Normal file
|
|
@ -0,0 +1,175 @@
|
|||
use super::*;
|
||||
|
||||
#[derive(Debug, Clone, PartialEq, Eq)]
|
||||
struct IdHeapItem {
|
||||
id: ID,
|
||||
lamport: Lamport,
|
||||
}
|
||||
|
||||
impl PartialOrd for IdHeapItem {
|
||||
fn partial_cmp(&self, other: &Self) -> Option<std::cmp::Ordering> {
|
||||
Some(self.lamport.cmp(&other.lamport).reverse())
|
||||
}
|
||||
}
|
||||
|
||||
impl Ord for IdHeapItem {
|
||||
fn cmp(&self, other: &Self) -> std::cmp::Ordering {
|
||||
self.lamport.cmp(&other.lamport).reverse()
|
||||
}
|
||||
}
|
||||
|
||||
pub(crate) fn iter_dag_with_vv<T>(dag: &dyn Dag<Node = T>) -> DagIteratorVV<'_, T> {
|
||||
DagIteratorVV {
|
||||
dag,
|
||||
vv_map: Default::default(),
|
||||
visited: VersionVector::new(),
|
||||
heap: BinaryHeap::new(),
|
||||
}
|
||||
}
|
||||
|
||||
pub(crate) fn iter_dag<T>(dag: &dyn Dag<Node = T>) -> DagIterator<'_, T> {
|
||||
DagIterator {
|
||||
dag,
|
||||
visited: VersionVector::new(),
|
||||
heap: BinaryHeap::new(),
|
||||
}
|
||||
}
|
||||
|
||||
pub struct DagIterator<'a, T> {
|
||||
dag: &'a dyn Dag<Node = T>,
|
||||
/// Because all deps' lamports are smaller than current node's lamport.
|
||||
/// We can use the lamport to sort the nodes so that each node's deps are processed before itself.
|
||||
///
|
||||
/// The ids in this heap are start ids of nodes. It won't be a id pointing to the middle of a node.
|
||||
heap: BinaryHeap<IdHeapItem>,
|
||||
visited: VersionVector,
|
||||
}
|
||||
|
||||
// TODO: Need benchmark on memory
|
||||
impl<'a, T: DagNode> Iterator for DagIterator<'a, T> {
|
||||
type Item = &'a T;
|
||||
|
||||
fn next(&mut self) -> Option<Self::Item> {
|
||||
if self.visited.is_empty() {
|
||||
if self.dag.vv().len() == 0 {
|
||||
return None;
|
||||
}
|
||||
|
||||
for (&client_id, _) in self.dag.vv().iter() {
|
||||
if let Some(node) = self.dag.get(ID::new(client_id, 0)) {
|
||||
self.heap.push(IdHeapItem {
|
||||
id: ID::new(client_id, 0),
|
||||
lamport: node.lamport_start(),
|
||||
});
|
||||
}
|
||||
|
||||
self.visited.insert(client_id, 0);
|
||||
}
|
||||
}
|
||||
|
||||
if !self.heap.is_empty() {
|
||||
let item = self.heap.pop().unwrap();
|
||||
let id = item.id;
|
||||
let node = self.dag.get(id).unwrap();
|
||||
debug_assert_eq!(id, node.id_start());
|
||||
|
||||
// push next node from the same client to the heap
|
||||
let next_id = id.inc(node.len() as i32);
|
||||
if self.dag.contains(next_id) {
|
||||
let next_node = self.dag.get(next_id).unwrap();
|
||||
self.heap.push(IdHeapItem {
|
||||
id: next_id,
|
||||
lamport: next_node.lamport_start(),
|
||||
});
|
||||
}
|
||||
|
||||
return Some(node);
|
||||
}
|
||||
|
||||
None
|
||||
}
|
||||
}
|
||||
|
||||
pub(crate) struct DagIteratorVV<'a, T> {
|
||||
dag: &'a dyn Dag<Node = T>,
|
||||
/// we should keep every nodes starting id inside this map
|
||||
vv_map: FxHashMap<ID, VersionVector>,
|
||||
/// Because all deps' lamports are smaller than current node's lamport.
|
||||
/// We can use the lamport to sort the nodes so that each node's deps are processed before itself.
|
||||
///
|
||||
/// The ids in this heap are start ids of nodes. It won't be a id pointing to the middle of a node.
|
||||
heap: BinaryHeap<IdHeapItem>,
|
||||
visited: VersionVector,
|
||||
}
|
||||
|
||||
// TODO: Need benchmark on memory
|
||||
impl<'a, T: DagNode> Iterator for DagIteratorVV<'a, T> {
|
||||
type Item = (&'a T, VersionVector);
|
||||
|
||||
fn next(&mut self) -> Option<Self::Item> {
|
||||
if self.vv_map.is_empty() {
|
||||
if self.dag.vv().len() == 0 {
|
||||
return None;
|
||||
}
|
||||
|
||||
for (&client_id, _) in self.dag.vv().iter() {
|
||||
let vv = VersionVector::new();
|
||||
if let Some(node) = self.dag.get(ID::new(client_id, 0)) {
|
||||
if node.lamport_start() == 0 {
|
||||
self.vv_map.insert(ID::new(client_id, 0), vv.clone());
|
||||
}
|
||||
|
||||
self.heap.push(IdHeapItem {
|
||||
id: ID::new(client_id, 0),
|
||||
lamport: node.lamport_start(),
|
||||
});
|
||||
}
|
||||
|
||||
self.visited.insert(client_id, 0);
|
||||
}
|
||||
}
|
||||
|
||||
if !self.heap.is_empty() {
|
||||
let item = self.heap.pop().unwrap();
|
||||
let id = item.id;
|
||||
let node = self.dag.get(id).unwrap();
|
||||
debug_assert_eq!(id, node.id_start());
|
||||
let mut vv = {
|
||||
// calculate vv
|
||||
let mut vv = None;
|
||||
for &dep_id in node.deps() {
|
||||
let dep = self.dag.get(dep_id).unwrap();
|
||||
let dep_vv = self.vv_map.get(&dep.id_start()).unwrap();
|
||||
if vv.is_none() {
|
||||
vv = Some(dep_vv.clone());
|
||||
} else {
|
||||
vv.as_mut().unwrap().merge(dep_vv);
|
||||
}
|
||||
|
||||
if dep.id_start() != dep_id {
|
||||
vv.as_mut().unwrap().set_end(dep_id);
|
||||
}
|
||||
}
|
||||
|
||||
vv.unwrap_or_else(VersionVector::new)
|
||||
};
|
||||
|
||||
vv.try_update_end(id);
|
||||
self.vv_map.insert(node.id_start(), vv.clone());
|
||||
|
||||
// push next node from the same client to the heap
|
||||
let next_id = id.inc(node.len() as i32);
|
||||
if self.dag.contains(next_id) {
|
||||
let next_node = self.dag.get(next_id).unwrap();
|
||||
self.heap.push(IdHeapItem {
|
||||
id: next_id,
|
||||
lamport: next_node.lamport_start(),
|
||||
});
|
||||
}
|
||||
|
||||
return Some((node, vv));
|
||||
}
|
||||
|
||||
None
|
||||
}
|
||||
}
|
||||
143
crates/loro-core/src/dag/mermaid.rs
Normal file
143
crates/loro-core/src/dag/mermaid.rs
Normal file
|
|
@ -0,0 +1,143 @@
|
|||
use rle::RleVec;
|
||||
|
||||
use super::*;
|
||||
struct BreakPoints {
|
||||
vv: VersionVector,
|
||||
break_points: FxHashMap<ClientID, FxHashSet<Counter>>,
|
||||
/// start ID to ID. The target ID may be in the middle of an op.
|
||||
///
|
||||
/// only includes links across different clients
|
||||
links: FxHashMap<ID, ID>,
|
||||
}
|
||||
|
||||
struct Output {
|
||||
clients: FxHashMap<ClientID, Vec<IdSpan>>,
|
||||
/// start ID to start ID.
|
||||
///
|
||||
/// only includes links across different clients
|
||||
links: FxHashMap<ID, ID>,
|
||||
}
|
||||
|
||||
fn to_str(output: Output) -> String {
|
||||
let mut s = String::new();
|
||||
let mut indent_level = 0;
|
||||
macro_rules! new_line {
|
||||
() => {
|
||||
s += "\n";
|
||||
for _ in 0..indent_level {
|
||||
s += " ";
|
||||
}
|
||||
};
|
||||
}
|
||||
s += "flowchart RL";
|
||||
indent_level += 1;
|
||||
new_line!();
|
||||
for (client_id, spans) in output.clients.iter() {
|
||||
s += format!("subgraph client{}", client_id).as_str();
|
||||
new_line!();
|
||||
let mut is_first = true;
|
||||
for id_span in spans.iter().rev() {
|
||||
if !is_first {
|
||||
s += " --> "
|
||||
}
|
||||
|
||||
is_first = false;
|
||||
s += format!(
|
||||
"{}-{}(\"c{}: [{}, {})\")",
|
||||
id_span.client_id,
|
||||
id_span.counter.from,
|
||||
id_span.client_id,
|
||||
id_span.counter.from,
|
||||
id_span.counter.to
|
||||
)
|
||||
.as_str();
|
||||
}
|
||||
|
||||
new_line!();
|
||||
s += "end";
|
||||
new_line!();
|
||||
new_line!();
|
||||
}
|
||||
|
||||
for (id_from, id_to) in output.links.iter() {
|
||||
s += format!(
|
||||
"{}-{} --> {}-{}",
|
||||
id_from.client_id, id_from.counter, id_to.client_id, id_to.counter
|
||||
)
|
||||
.as_str();
|
||||
new_line!();
|
||||
}
|
||||
|
||||
s
|
||||
}
|
||||
|
||||
fn break_points_to_output(input: BreakPoints) -> Output {
|
||||
let mut output = Output {
|
||||
clients: FxHashMap::default(),
|
||||
links: FxHashMap::default(),
|
||||
};
|
||||
let breaks: FxHashMap<ClientID, Vec<Counter>> = input
|
||||
.break_points
|
||||
.into_iter()
|
||||
.map(|(client_id, set)| {
|
||||
let mut vec: Vec<Counter> = set.iter().cloned().collect();
|
||||
vec.sort();
|
||||
(client_id, vec)
|
||||
})
|
||||
.collect();
|
||||
for (client_id, break_points) in breaks.iter() {
|
||||
let mut spans = vec![];
|
||||
for (from, to) in break_points.iter().zip(break_points.iter().skip(1)) {
|
||||
spans.push(IdSpan::new(*client_id, *from, *to));
|
||||
}
|
||||
output.clients.insert(*client_id, spans);
|
||||
}
|
||||
|
||||
for (id_from, id_to) in input.links.iter() {
|
||||
let client_breaks = breaks.get(&id_to.client_id).unwrap();
|
||||
match client_breaks.binary_search(&id_to.counter) {
|
||||
Ok(_) => {
|
||||
output.links.insert(*id_from, *id_to);
|
||||
}
|
||||
Err(index) => {
|
||||
output
|
||||
.links
|
||||
.insert(*id_from, ID::new(id_to.client_id, client_breaks[index - 1]));
|
||||
}
|
||||
}
|
||||
}
|
||||
output
|
||||
}
|
||||
|
||||
fn get_dag_break_points<T: DagNode>(dag: &impl Dag<Node = T>) -> BreakPoints {
|
||||
let mut break_points = BreakPoints {
|
||||
vv: dag.vv(),
|
||||
break_points: FxHashMap::default(),
|
||||
links: FxHashMap::default(),
|
||||
};
|
||||
|
||||
for node in dag.iter() {
|
||||
let id = node.id_start();
|
||||
let set = break_points.break_points.entry(id.client_id).or_default();
|
||||
set.insert(id.counter);
|
||||
set.insert(id.counter + node.len() as Counter);
|
||||
for dep in node.deps() {
|
||||
if dep.client_id == id.client_id {
|
||||
continue;
|
||||
}
|
||||
|
||||
break_points
|
||||
.break_points
|
||||
.entry(dep.client_id)
|
||||
.or_default()
|
||||
.insert(dep.counter);
|
||||
break_points.links.insert(id, *dep);
|
||||
}
|
||||
}
|
||||
|
||||
break_points
|
||||
}
|
||||
|
||||
pub(crate) fn dag_to_mermaid<T: DagNode>(dag: &impl Dag<Node = T>) -> String {
|
||||
to_str(break_points_to_output(get_dag_break_points(dag)))
|
||||
}
|
||||
635
crates/loro-core/src/dag/test.rs
Normal file
635
crates/loro-core/src/dag/test.rs
Normal file
|
|
@ -0,0 +1,635 @@
|
|||
#![cfg(test)]
|
||||
|
||||
use proptest::proptest;
|
||||
|
||||
use super::*;
|
||||
use crate::{
|
||||
array_mut_ref,
|
||||
change::Lamport,
|
||||
id::{ClientID, Counter, ID},
|
||||
span::{CounterSpan, IdSpan},
|
||||
};
|
||||
use std::collections::HashSet;
|
||||
use std::iter::FromIterator;
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Clone)]
|
||||
struct TestNode {
|
||||
id: ID,
|
||||
lamport: Lamport,
|
||||
len: usize,
|
||||
deps: Vec<ID>,
|
||||
}
|
||||
|
||||
impl TestNode {
|
||||
fn new(id: ID, lamport: Lamport, deps: Vec<ID>, len: usize) -> Self {
|
||||
Self {
|
||||
id,
|
||||
lamport,
|
||||
deps,
|
||||
len,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
impl DagNode for TestNode {
|
||||
fn id_start(&self) -> ID {
|
||||
self.id
|
||||
}
|
||||
fn lamport_start(&self) -> Lamport {
|
||||
self.lamport
|
||||
}
|
||||
fn len(&self) -> usize {
|
||||
self.len
|
||||
}
|
||||
fn deps(&self) -> &Vec<ID> {
|
||||
&self.deps
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, PartialEq, Eq)]
|
||||
struct TestDag {
|
||||
nodes: FxHashMap<ClientID, Vec<TestNode>>,
|
||||
frontier: Vec<ID>,
|
||||
version_vec: VersionVector,
|
||||
next_lamport: Lamport,
|
||||
client_id: ClientID,
|
||||
}
|
||||
|
||||
impl Dag for TestDag {
|
||||
type Node = TestNode;
|
||||
|
||||
fn get(&self, id: ID) -> Option<&Self::Node> {
|
||||
self.nodes.get(&id.client_id)?.iter().find(|node| {
|
||||
id.counter >= node.id.counter && id.counter < node.id.counter + node.len as Counter
|
||||
})
|
||||
}
|
||||
|
||||
fn frontier(&self) -> &[ID] {
|
||||
&self.frontier
|
||||
}
|
||||
|
||||
fn roots(&self) -> Vec<&Self::Node> {
|
||||
self.nodes.iter().map(|(_, v)| &v[0]).collect()
|
||||
}
|
||||
|
||||
fn contains(&self, id: ID) -> bool {
|
||||
self.version_vec
|
||||
.get(&id.client_id)
|
||||
.and_then(|x| if *x > id.counter { Some(()) } else { None })
|
||||
.is_some()
|
||||
}
|
||||
|
||||
fn vv(&self) -> VersionVector {
|
||||
self.version_vec.clone()
|
||||
}
|
||||
}
|
||||
|
||||
impl TestDag {
|
||||
pub fn new(client_id: ClientID) -> Self {
|
||||
Self {
|
||||
nodes: FxHashMap::default(),
|
||||
frontier: Vec::new(),
|
||||
version_vec: VersionVector::new(),
|
||||
next_lamport: 0,
|
||||
client_id,
|
||||
}
|
||||
}
|
||||
|
||||
fn get_last_node(&mut self) -> &mut TestNode {
|
||||
self.nodes
|
||||
.get_mut(&self.client_id)
|
||||
.unwrap()
|
||||
.last_mut()
|
||||
.unwrap()
|
||||
}
|
||||
|
||||
fn push(&mut self, len: usize) {
|
||||
let client_id = self.client_id;
|
||||
let counter = self.version_vec.entry(client_id).or_insert(0);
|
||||
let id = ID::new(client_id, *counter);
|
||||
*counter += len as Counter;
|
||||
let deps = std::mem::replace(&mut self.frontier, vec![id]);
|
||||
self.nodes
|
||||
.entry(client_id)
|
||||
.or_insert(vec![])
|
||||
.push(TestNode::new(id, self.next_lamport, deps, len));
|
||||
self.next_lamport += len as u32;
|
||||
}
|
||||
|
||||
fn merge(&mut self, other: &TestDag) {
|
||||
let mut pending = Vec::new();
|
||||
for (_, nodes) in other.nodes.iter() {
|
||||
for (i, node) in nodes.iter().enumerate() {
|
||||
if self._try_push_node(node, &mut pending, i) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
let mut current = pending;
|
||||
let mut pending = Vec::new();
|
||||
while !pending.is_empty() || !current.is_empty() {
|
||||
if current.is_empty() {
|
||||
std::mem::swap(&mut pending, &mut current);
|
||||
}
|
||||
|
||||
let (client_id, index) = current.pop().unwrap();
|
||||
let node_vec = other.nodes.get(&client_id).unwrap();
|
||||
#[allow(clippy::needless_range_loop)]
|
||||
for i in index..node_vec.len() {
|
||||
let node = &node_vec[i];
|
||||
if self._try_push_node(node, &mut pending, i) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn _try_push_node(
|
||||
&mut self,
|
||||
node: &TestNode,
|
||||
pending: &mut Vec<(u64, usize)>,
|
||||
i: usize,
|
||||
) -> bool {
|
||||
let client_id = node.id.client_id;
|
||||
if self.contains(node.id) {
|
||||
return false;
|
||||
}
|
||||
if node.deps.iter().any(|dep| !self.contains(*dep)) {
|
||||
pending.push((client_id, i));
|
||||
return true;
|
||||
}
|
||||
update_frontier(
|
||||
&mut self.frontier,
|
||||
node.id.inc((node.len() - 1) as Counter),
|
||||
&node.deps,
|
||||
);
|
||||
self.nodes
|
||||
.entry(client_id)
|
||||
.or_insert(vec![])
|
||||
.push(node.clone());
|
||||
self.version_vec
|
||||
.insert(client_id, node.id.counter + node.len as Counter);
|
||||
self.next_lamport = self.next_lamport.max(node.lamport + node.len as u32);
|
||||
false
|
||||
}
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_dag() {
|
||||
let mut a = TestDag::new(0);
|
||||
let mut b = TestDag::new(1);
|
||||
a.push(1);
|
||||
assert_eq!(a.frontier().len(), 1);
|
||||
assert_eq!(a.frontier()[0].counter, 0);
|
||||
b.push(1);
|
||||
a.merge(&b);
|
||||
assert_eq!(a.frontier().len(), 2);
|
||||
a.push(1);
|
||||
assert_eq!(a.frontier().len(), 1);
|
||||
// a: 0 --(merge)--- 1
|
||||
// ↑
|
||||
// |
|
||||
// b: 0 ----
|
||||
assert_eq!(
|
||||
a.frontier()[0],
|
||||
ID {
|
||||
client_id: 0,
|
||||
counter: 1
|
||||
}
|
||||
);
|
||||
|
||||
// a: 0 --(merge)--- 1 --- 2 -------
|
||||
// ↑ |
|
||||
// | ↓
|
||||
// b: 0 ------------1----------(merge)
|
||||
a.push(1);
|
||||
b.push(1);
|
||||
b.merge(&a);
|
||||
assert_eq!(b.next_lamport, 3);
|
||||
assert_eq!(b.frontier().len(), 2);
|
||||
assert_eq!(
|
||||
b.find_common_ancestor(ID::new(0, 2), ID::new(1, 1)),
|
||||
Some(ID::new(1, 0))
|
||||
);
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone, Copy)]
|
||||
struct Interaction {
|
||||
dag_idx: usize,
|
||||
merge_with: Option<usize>,
|
||||
len: usize,
|
||||
}
|
||||
|
||||
impl Interaction {
|
||||
fn gen(rng: &mut impl rand::Rng, num: usize) -> Self {
|
||||
if rng.gen_bool(0.5) {
|
||||
let dag_idx = rng.gen_range(0..num);
|
||||
let merge_with = (rng.gen_range(1..num - 1) + dag_idx) % num;
|
||||
Self {
|
||||
dag_idx,
|
||||
merge_with: Some(merge_with),
|
||||
len: rng.gen_range(1..10),
|
||||
}
|
||||
} else {
|
||||
Self {
|
||||
dag_idx: rng.gen_range(0..num),
|
||||
merge_with: None,
|
||||
len: rng.gen_range(1..10),
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn apply(&self, dags: &mut [TestDag]) {
|
||||
if let Some(merge_with) = self.merge_with {
|
||||
if merge_with != self.dag_idx {
|
||||
let (from, to) = array_mut_ref!(dags, [self.dag_idx, merge_with]);
|
||||
from.merge(to);
|
||||
}
|
||||
}
|
||||
|
||||
dags[self.dag_idx].push(self.len);
|
||||
}
|
||||
}
|
||||
|
||||
mod iter {
|
||||
use super::*;
|
||||
|
||||
#[test]
|
||||
fn test() {
|
||||
let mut a = TestDag::new(0);
|
||||
let mut b = TestDag::new(1);
|
||||
// 0-0
|
||||
a.push(1);
|
||||
// 1-0
|
||||
b.push(1);
|
||||
a.merge(&b);
|
||||
// 0-1
|
||||
a.push(1);
|
||||
b.merge(&a);
|
||||
// 1-1
|
||||
b.push(1);
|
||||
a.merge(&b);
|
||||
// 0-2
|
||||
a.push(1);
|
||||
|
||||
let mut count = 0;
|
||||
for (node, vv) in a.iter_with_vv() {
|
||||
count += 1;
|
||||
if node.id == ID::new(0, 0) {
|
||||
assert_eq!(vv, vec![ID::new(0, 0)].into());
|
||||
} else if node.id == ID::new(0, 2) {
|
||||
assert_eq!(vv, vec![ID::new(0, 2), ID::new(1, 1)].into());
|
||||
}
|
||||
}
|
||||
|
||||
assert_eq!(count, 5);
|
||||
}
|
||||
}
|
||||
|
||||
mod mermaid {
|
||||
use rle::Mergable;
|
||||
|
||||
use super::*;
|
||||
|
||||
#[test]
|
||||
fn simple() {
|
||||
let mut a = TestDag::new(0);
|
||||
let mut b = TestDag::new(1);
|
||||
// 0-0
|
||||
a.push(1);
|
||||
// 1-0
|
||||
b.push(1);
|
||||
a.merge(&b);
|
||||
// 0-1
|
||||
a.push(1);
|
||||
b.merge(&a);
|
||||
// 1-1
|
||||
b.push(1);
|
||||
a.merge(&b);
|
||||
// 0-2
|
||||
a.push(1);
|
||||
|
||||
println!("{}", a.mermaid());
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn three() {
|
||||
let mut a = TestDag::new(0);
|
||||
let mut b = TestDag::new(1);
|
||||
let mut c = TestDag::new(2);
|
||||
a.push(10);
|
||||
b.merge(&a);
|
||||
b.push(3);
|
||||
c.merge(&b);
|
||||
c.push(4);
|
||||
a.merge(&c);
|
||||
a.push(2);
|
||||
b.merge(&a);
|
||||
println!("{}", b.mermaid());
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn gen() {
|
||||
let num = 5;
|
||||
let mut rng = rand::thread_rng();
|
||||
let mut dags = (0..num).map(TestDag::new).collect::<Vec<_>>();
|
||||
for _ in 0..100 {
|
||||
Interaction::gen(&mut rng, num as usize).apply(&mut dags);
|
||||
}
|
||||
for i in 1..num {
|
||||
let (a, other) = array_mut_ref!(&mut dags, [0, i as usize]);
|
||||
a.merge(other);
|
||||
}
|
||||
println!("{}", dags[0].mermaid());
|
||||
}
|
||||
}
|
||||
|
||||
mod get_version_vector {
|
||||
use super::*;
|
||||
|
||||
#[test]
|
||||
fn vv() {
|
||||
let mut a = TestDag::new(0);
|
||||
let mut b = TestDag::new(1);
|
||||
a.push(1);
|
||||
b.push(1);
|
||||
a.merge(&b);
|
||||
a.push(1);
|
||||
let actual = a.get_vv(ID::new(0, 0));
|
||||
assert_eq!(actual, vec![ID::new(0, 0)].into());
|
||||
let actual = a.get_vv(ID::new(0, 1));
|
||||
assert_eq!(actual, vec![ID::new(0, 1), ID::new(1, 0)].into());
|
||||
|
||||
let mut c = TestDag::new(2);
|
||||
c.merge(&a);
|
||||
b.push(1);
|
||||
c.merge(&b);
|
||||
c.push(1);
|
||||
let actual = c.get_vv(ID::new(2, 0));
|
||||
assert_eq!(
|
||||
actual,
|
||||
vec![ID::new(0, 1), ID::new(1, 1), ID::new(2, 0)].into()
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
mod find_path {
|
||||
use super::*;
|
||||
|
||||
#[test]
|
||||
fn no_path() {
|
||||
let mut a = TestDag::new(0);
|
||||
let mut b = TestDag::new(1);
|
||||
a.push(1);
|
||||
b.push(1);
|
||||
a.merge(&b);
|
||||
let actual = a.find_path(ID::new(0, 0), ID::new(1, 0));
|
||||
assert_eq!(actual, None);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn one_path() {
|
||||
let mut a = TestDag::new(0);
|
||||
let mut b = TestDag::new(1);
|
||||
// 0 - 0
|
||||
a.push(1);
|
||||
b.merge(&a);
|
||||
// 1 - 0
|
||||
b.push(1);
|
||||
// 0 - 1
|
||||
a.push(1);
|
||||
a.merge(&b);
|
||||
let actual = a.find_path(ID::new(0, 1), ID::new(1, 0));
|
||||
assert_eq!(
|
||||
actual,
|
||||
Some(Path {
|
||||
retreat: vec![IdSpan::new(0, 1, 0)],
|
||||
forward: vec![IdSpan::new(1, 0, 1)],
|
||||
})
|
||||
);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn middle() {
|
||||
let mut a = TestDag::new(0);
|
||||
let mut b = TestDag::new(1);
|
||||
a.push(4);
|
||||
b.push(1);
|
||||
b.push(1);
|
||||
let node = b.get_last_node();
|
||||
node.deps.push(ID::new(0, 2));
|
||||
b.merge(&a);
|
||||
let actual = b.find_path(ID::new(0, 3), ID::new(1, 1));
|
||||
assert_eq!(
|
||||
actual,
|
||||
Some(Path {
|
||||
retreat: vec![IdSpan::new(0, 3, 2)],
|
||||
forward: vec![IdSpan::new(1, 1, 2)],
|
||||
})
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
mod find_common_ancestors {
|
||||
use super::*;
|
||||
|
||||
#[test]
|
||||
fn no_common_ancestors() {
|
||||
let mut a = TestDag::new(0);
|
||||
let mut b = TestDag::new(1);
|
||||
a.push(1);
|
||||
b.push(1);
|
||||
a.merge(&b);
|
||||
let actual = a.find_common_ancestor(ID::new(0, 0), ID::new(1, 0));
|
||||
assert_eq!(actual, None);
|
||||
|
||||
// interactions between b and c
|
||||
let mut c = TestDag::new(2);
|
||||
c.merge(&b);
|
||||
c.push(2);
|
||||
b.merge(&c);
|
||||
b.push(3);
|
||||
|
||||
// should no exist any common ancestor between a and b
|
||||
let actual = a.find_common_ancestor(ID::new(0, 0), ID::new(1, 0));
|
||||
assert_eq!(actual, None);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn dep_in_middle() {
|
||||
let mut a = TestDag::new(0);
|
||||
let mut b = TestDag::new(1);
|
||||
a.push(4);
|
||||
b.push(4);
|
||||
b.push(5);
|
||||
b.merge(&a);
|
||||
b.frontier.retain(|x| x.client_id == 1);
|
||||
let k = b.nodes.get_mut(&1).unwrap();
|
||||
k[1].deps.push(ID::new(0, 2));
|
||||
assert_eq!(
|
||||
b.find_common_ancestor(ID::new(0, 3), ID::new(1, 8)),
|
||||
Some(ID::new(0, 2))
|
||||
);
|
||||
}
|
||||
|
||||
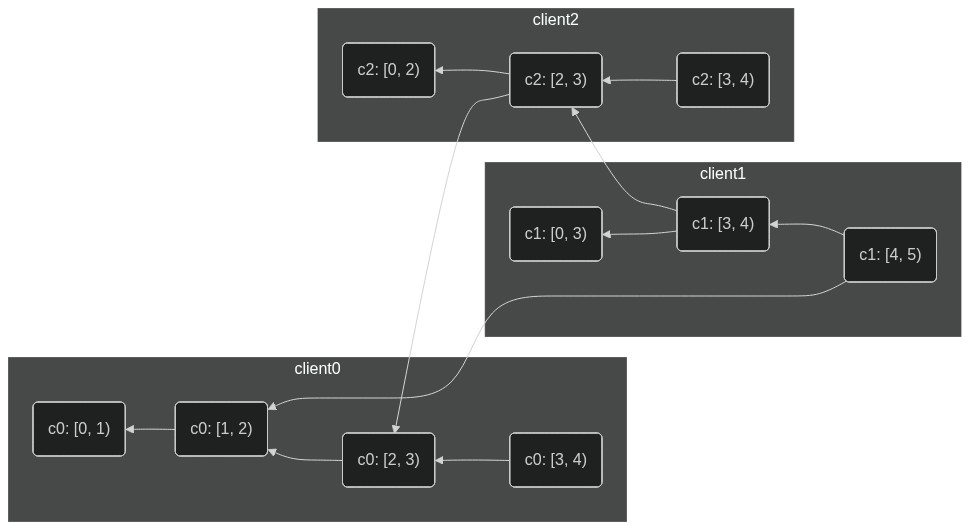
/// 
|
||||
#[test]
|
||||
fn large_lamport_with_longer_path() {
|
||||
let mut a0 = TestDag::new(0);
|
||||
let mut a1 = TestDag::new(1);
|
||||
let mut a2 = TestDag::new(2);
|
||||
|
||||
a0.push(3);
|
||||
a1.push(3);
|
||||
a2.push(2);
|
||||
a2.merge(&a0);
|
||||
a2.push(1);
|
||||
a1.merge(&a2);
|
||||
a2.push(1);
|
||||
a1.push(1);
|
||||
a1.merge(&a2);
|
||||
a1.push(1);
|
||||
a1.nodes
|
||||
.get_mut(&1)
|
||||
.unwrap()
|
||||
.last_mut()
|
||||
.unwrap()
|
||||
.deps
|
||||
.push(ID::new(0, 1));
|
||||
a0.push(1);
|
||||
a1.merge(&a2);
|
||||
a1.merge(&a0);
|
||||
assert_eq!(
|
||||
a1.find_common_ancestor(ID::new(0, 3), ID::new(1, 4)),
|
||||
Some(ID::new(0, 2))
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(not(no_proptest))]
|
||||
mod find_common_ancestors_proptest {
|
||||
use proptest::prelude::*;
|
||||
|
||||
use crate::{array_mut_ref, unsafe_array_mut_ref};
|
||||
|
||||
use super::*;
|
||||
|
||||
prop_compose! {
|
||||
fn gen_interaction(num: usize) (
|
||||
dag_idx in 0..num,
|
||||
merge_with in 0..num,
|
||||
length in 1..10,
|
||||
should_merge in 0..2
|
||||
) -> Interaction {
|
||||
Interaction {
|
||||
dag_idx,
|
||||
merge_with: if should_merge == 1 && merge_with != dag_idx { Some(merge_with) } else { None },
|
||||
len: length as usize,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
proptest! {
|
||||
#[test]
|
||||
fn test_2dags(
|
||||
before_merged_insertions in prop::collection::vec(gen_interaction(2), 0..300),
|
||||
after_merged_insertions in prop::collection::vec(gen_interaction(2), 0..300)
|
||||
) {
|
||||
test(2, before_merged_insertions, after_merged_insertions)?;
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_4dags(
|
||||
before_merged_insertions in prop::collection::vec(gen_interaction(4), 0..300),
|
||||
after_merged_insertions in prop::collection::vec(gen_interaction(4), 0..300)
|
||||
) {
|
||||
test(4, before_merged_insertions, after_merged_insertions)?;
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_10dags(
|
||||
before_merged_insertions in prop::collection::vec(gen_interaction(10), 0..300),
|
||||
after_merged_insertions in prop::collection::vec(gen_interaction(10), 0..300)
|
||||
) {
|
||||
test(10, before_merged_insertions, after_merged_insertions)?;
|
||||
}
|
||||
}
|
||||
|
||||
fn preprocess(interactions: &mut [Interaction], num: i32) {
|
||||
for interaction in interactions.iter_mut() {
|
||||
interaction.dag_idx %= num as usize;
|
||||
if let Some(ref mut merge_with) = interaction.merge_with {
|
||||
*merge_with %= num as usize;
|
||||
if *merge_with == interaction.dag_idx {
|
||||
*merge_with = (*merge_with + 1) % num as usize;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn test(
|
||||
dag_num: i32,
|
||||
mut before_merge_insertion: Vec<Interaction>,
|
||||
mut after_merge_insertion: Vec<Interaction>,
|
||||
) -> Result<(), TestCaseError> {
|
||||
preprocess(&mut before_merge_insertion, dag_num);
|
||||
preprocess(&mut after_merge_insertion, dag_num);
|
||||
let mut dags = Vec::new();
|
||||
for i in 0..dag_num {
|
||||
dags.push(TestDag::new(i as ClientID));
|
||||
}
|
||||
|
||||
for interaction in before_merge_insertion {
|
||||
apply(interaction, &mut dags);
|
||||
}
|
||||
|
||||
let (dag0,): (&mut TestDag,) = unsafe_array_mut_ref!(&mut dags, [0]);
|
||||
for dag in &dags[1..] {
|
||||
dag0.merge(dag);
|
||||
}
|
||||
|
||||
dag0.push(1);
|
||||
let expected = dag0.frontier()[0];
|
||||
for dag in &mut dags[1..] {
|
||||
dag.merge(dag0);
|
||||
}
|
||||
for interaction in after_merge_insertion.iter_mut() {
|
||||
if let Some(merge) = interaction.merge_with {
|
||||
// odd dag merges with the odd
|
||||
// even dag merges with the even
|
||||
if merge % 2 != interaction.dag_idx % 2 {
|
||||
interaction.merge_with = None;
|
||||
}
|
||||
}
|
||||
|
||||
apply(*interaction, &mut dags);
|
||||
}
|
||||
|
||||
let (dag0, dag1) = array_mut_ref!(&mut dags, [0, 1]);
|
||||
dag1.push(1);
|
||||
dag0.merge(dag1);
|
||||
// dbg!(dag0, dag1, expected);
|
||||
let a = dags[0].nodes.get(&0).unwrap().last().unwrap().id;
|
||||
let b = dags[1].nodes.get(&1).unwrap().last().unwrap().id;
|
||||
let actual = dags[0].find_common_ancestor(a, b);
|
||||
prop_assert_eq!(actual.unwrap(), expected);
|
||||
Ok(())
|
||||
}
|
||||
|
||||
fn apply(interaction: Interaction, dags: &mut [TestDag]) {
|
||||
let Interaction {
|
||||
dag_idx,
|
||||
len,
|
||||
merge_with,
|
||||
} = interaction;
|
||||
if let Some(merge_with) = merge_with {
|
||||
let (dag, merge_target): (&mut TestDag, &mut TestDag) =
|
||||
array_mut_ref!(dags, [dag_idx, merge_with]);
|
||||
dag.push(len);
|
||||
dag.merge(merge_target);
|
||||
} else {
|
||||
dags[dag_idx].push(len);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
@ -1,21 +1,21 @@
|
|||
use serde::Serialize;
|
||||
|
||||
pub type ClientID = u64;
|
||||
pub type Counter = u32;
|
||||
pub type Counter = i32;
|
||||
|
||||
#[derive(PartialEq, Eq, Hash, Clone, Debug, Copy, PartialOrd, Ord, Serialize)]
|
||||
pub struct ID {
|
||||
pub client_id: u64,
|
||||
pub counter: u32,
|
||||
pub counter: Counter,
|
||||
}
|
||||
|
||||
pub const ROOT_ID: ID = ID {
|
||||
client_id: u64::MAX,
|
||||
counter: u32::MAX,
|
||||
counter: i32::MAX,
|
||||
};
|
||||
|
||||
impl ID {
|
||||
pub fn new(client_id: u64, counter: u32) -> Self {
|
||||
pub fn new(client_id: u64, counter: Counter) -> Self {
|
||||
ID { client_id, counter }
|
||||
}
|
||||
|
||||
|
|
@ -28,11 +28,11 @@ impl ID {
|
|||
}
|
||||
|
||||
#[inline]
|
||||
pub(crate) fn is_connected_id(&self, other: &Self, self_len: u32) -> bool {
|
||||
self.client_id == other.client_id && self.counter + self_len == other.counter
|
||||
pub(crate) fn is_connected_id(&self, other: &Self, self_len: usize) -> bool {
|
||||
self.client_id == other.client_id && self.counter + self_len as Counter == other.counter
|
||||
}
|
||||
|
||||
pub fn inc(&self, inc: u32) -> Self {
|
||||
pub fn inc(&self, inc: i32) -> Self {
|
||||
ID {
|
||||
client_id: self.client_id,
|
||||
counter: self.counter + inc,
|
||||
|
|
|
|||
|
|
@ -1,22 +1,24 @@
|
|||
//! # Loro
|
||||
//! loro-core is a CRDT framework.
|
||||
//!
|
||||
//!
|
||||
#![allow(dead_code, unused_imports, clippy::explicit_auto_deref)]
|
||||
//!
|
||||
#![allow(dead_code, unused_imports)]
|
||||
|
||||
pub mod change;
|
||||
pub mod configure;
|
||||
pub mod container;
|
||||
pub mod dag;
|
||||
pub mod id;
|
||||
pub mod log_store;
|
||||
pub mod op;
|
||||
pub mod version;
|
||||
|
||||
mod error;
|
||||
mod log_store;
|
||||
mod loro;
|
||||
mod smstring;
|
||||
mod snapshot;
|
||||
mod span;
|
||||
#[cfg(test)]
|
||||
mod tests;
|
||||
mod value;
|
||||
|
||||
|
|
@ -31,5 +33,6 @@ pub use container::ContainerType;
|
|||
pub use log_store::LogStore;
|
||||
pub use loro::*;
|
||||
pub use value::LoroValue;
|
||||
pub use version::VersionVector;
|
||||
|
||||
use string_cache::DefaultAtom;
|
||||
|
|
|
|||
|
|
@ -1,3 +1,6 @@
|
|||
//! [LogStore] stores all the [Change]s and [Op]s. It's also a [DAG][crate::dag];
|
||||
//!
|
||||
//!
|
||||
mod iter;
|
||||
use pin_project::pin_project;
|
||||
use std::{collections::BinaryHeap, marker::PhantomPinned, pin::Pin, ptr::NonNull};
|
||||
|
|
@ -38,6 +41,8 @@ impl Default for GcConfig {
|
|||
|
||||
/// Entry of the loro inner state.
|
||||
/// This is a self-referential structure. So it need to be pinned.
|
||||
///
|
||||
/// `frontier`s are the Changes without children in the DAG (there is no dep pointing to them)
|
||||
#[pin_project]
|
||||
pub struct LogStore {
|
||||
changes: FxHashMap<ClientID, RleVec<Change, ChangeMergeCfg>>,
|
||||
|
|
|
|||
|
|
@ -61,7 +61,7 @@ impl<'a> Iterator for OpIter<'a> {
|
|||
self.heap.push(Reverse(OpProxy::new(
|
||||
change,
|
||||
op,
|
||||
Some(start..(op.len() as u32)),
|
||||
Some(start..(op.len() as Counter)),
|
||||
)));
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -20,3 +20,68 @@ macro_rules! fx_map {
|
|||
}
|
||||
};
|
||||
}
|
||||
|
||||
#[macro_export]
|
||||
macro_rules! unsafe_array_mut_ref {
|
||||
($arr:expr, [$($idx:expr),*]) => {
|
||||
{
|
||||
unsafe {
|
||||
(
|
||||
$(
|
||||
{ &mut *(&mut $arr[$idx] as *mut _) }
|
||||
),*,
|
||||
)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#[macro_export]
|
||||
macro_rules! array_mut_ref {
|
||||
($arr:expr, [$a0:expr, $a1:expr]) => {{
|
||||
#[inline]
|
||||
fn borrow_mut_ref<T>(arr: &mut [T], a0: usize, a1: usize) -> (&mut T, &mut T) {
|
||||
debug_assert!(a0 != a1);
|
||||
unsafe {
|
||||
(
|
||||
&mut *(&mut arr[a0] as *mut _),
|
||||
&mut *(&mut arr[a1] as *mut _),
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
borrow_mut_ref($arr, $a0, $a1)
|
||||
}};
|
||||
($arr:expr, [$a0:expr, $a1:expr, $a2:expr]) => {{
|
||||
#[inline]
|
||||
fn borrow_mut_ref<T>(
|
||||
arr: &mut [T],
|
||||
a0: usize,
|
||||
a1: usize,
|
||||
a2: usize,
|
||||
) -> (&mut T, &mut T, &mut T) {
|
||||
debug_assert!(a0 != a1 && a1 != a2 && a0 != a2);
|
||||
unsafe {
|
||||
(
|
||||
&mut *(&mut arr[a0] as *mut _),
|
||||
&mut *(&mut arr[a1] as *mut _),
|
||||
&mut *(&mut arr[a2] as *mut _),
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
borrow_mut_ref($arr, $a0, $a1, $a2)
|
||||
}};
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn test_macro() {
|
||||
let mut arr = vec![100, 101, 102, 103];
|
||||
let (a, b, c) = array_mut_ref!(&mut arr, [1, 2, 3]);
|
||||
assert_eq!(*a, 101);
|
||||
assert_eq!(*b, 102);
|
||||
*a = 50;
|
||||
*b = 51;
|
||||
assert!(arr[1] == 50);
|
||||
assert!(arr[2] == 51);
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
use crate::{
|
||||
container::ContainerID,
|
||||
id::ID,
|
||||
id::{Counter, ID},
|
||||
span::{CounterSpan, IdSpan},
|
||||
};
|
||||
use rle::{HasLength, Mergable, RleVec, Sliceable};
|
||||
|
|
@ -78,7 +78,7 @@ impl Op {
|
|||
|
||||
impl Mergable for Op {
|
||||
fn is_mergable(&self, other: &Self, cfg: &()) -> bool {
|
||||
self.id.is_connected_id(&other.id, self.len() as u32)
|
||||
self.id.is_connected_id(&other.id, self.len())
|
||||
&& self.content.is_mergable(&other.content, cfg)
|
||||
&& self.container == other.container
|
||||
}
|
||||
|
|
@ -124,7 +124,7 @@ impl Sliceable for Op {
|
|||
Op {
|
||||
id: ID {
|
||||
client_id: self.id.client_id,
|
||||
counter: (self.id.counter + from as u32),
|
||||
counter: (self.id.counter + from as Counter),
|
||||
},
|
||||
content,
|
||||
container: self.container.clone(),
|
||||
|
|
|
|||
|
|
@ -2,14 +2,16 @@ use std::ops::Range;
|
|||
|
||||
use rle::{HasLength, Sliceable};
|
||||
|
||||
use crate::{container::ContainerID, Change, Lamport, Op, OpContent, OpType, Timestamp, ID};
|
||||
use crate::{
|
||||
container::ContainerID, id::Counter, Change, Lamport, Op, OpContent, OpType, Timestamp, ID,
|
||||
};
|
||||
|
||||
/// OpProxy represents a slice of an Op
|
||||
pub struct OpProxy<'a> {
|
||||
change: &'a Change,
|
||||
op: &'a Op,
|
||||
/// slice range of the op, op[slice_range]
|
||||
slice_range: Range<u32>,
|
||||
slice_range: Range<Counter>,
|
||||
}
|
||||
|
||||
impl PartialEq for OpProxy<'_> {
|
||||
|
|
@ -43,20 +45,21 @@ impl Ord for OpProxy<'_> {
|
|||
}
|
||||
|
||||
impl<'a> OpProxy<'a> {
|
||||
pub fn new(change: &'a Change, op: &'a Op, range: Option<Range<u32>>) -> Self {
|
||||
pub fn new(change: &'a Change, op: &'a Op, range: Option<Range<Counter>>) -> Self {
|
||||
OpProxy {
|
||||
change,
|
||||
op,
|
||||
slice_range: if let Some(range) = range {
|
||||
range
|
||||
} else {
|
||||
0..op.len() as u32
|
||||
0..op.len() as Counter
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
pub fn lamport(&self) -> Lamport {
|
||||
self.change.lamport + self.op.id.counter - self.change.id.counter + self.slice_range.start
|
||||
self.change.lamport + self.op.id.counter as Lamport - self.change.id.counter as Lamport
|
||||
+ self.slice_range.start as Lamport
|
||||
}
|
||||
|
||||
pub fn id(&self) -> ID {
|
||||
|
|
@ -74,7 +77,7 @@ impl<'a> OpProxy<'a> {
|
|||
self.op
|
||||
}
|
||||
|
||||
pub fn slice_range(&self) -> &Range<u32> {
|
||||
pub fn slice_range(&self) -> &Range<Counter> {
|
||||
&self.slice_range
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -13,6 +13,19 @@ impl CounterSpan {
|
|||
CounterSpan { from, to }
|
||||
}
|
||||
|
||||
#[inline]
|
||||
pub fn reverse(&mut self) {
|
||||
if self.from == self.to {
|
||||
return;
|
||||
}
|
||||
|
||||
if self.from < self.to {
|
||||
(self.from, self.to) = (self.to - 1, self.from - 1);
|
||||
} else {
|
||||
(self.from, self.to) = (self.to + 1, self.from + 1);
|
||||
}
|
||||
}
|
||||
|
||||
#[inline]
|
||||
pub fn min(&self) -> Counter {
|
||||
if self.from < self.to {
|
||||
|
|
@ -81,6 +94,14 @@ pub struct IdSpan {
|
|||
}
|
||||
|
||||
impl IdSpan {
|
||||
#[inline]
|
||||
pub fn new(client_id: ClientID, from: Counter, to: Counter) -> Self {
|
||||
Self {
|
||||
client_id,
|
||||
counter: CounterSpan { from, to },
|
||||
}
|
||||
}
|
||||
|
||||
#[inline]
|
||||
pub fn min(&self) -> Counter {
|
||||
self.counter.min()
|
||||
|
|
|
|||
|
|
@ -96,7 +96,7 @@ impl LoroValue {
|
|||
}
|
||||
|
||||
#[inline]
|
||||
pub fn to_map(&self) -> Option<&FxHashMap<InternalString, LoroValue>> {
|
||||
pub fn as_map(&self) -> Option<&FxHashMap<InternalString, LoroValue>> {
|
||||
match self {
|
||||
LoroValue::Map(m) => Some(m),
|
||||
_ => None,
|
||||
|
|
@ -104,7 +104,7 @@ impl LoroValue {
|
|||
}
|
||||
|
||||
#[inline]
|
||||
pub fn to_list(&self) -> Option<&Vec<LoroValue>> {
|
||||
pub fn as_list(&self) -> Option<&Vec<LoroValue>> {
|
||||
match self {
|
||||
LoroValue::List(l) => Some(l),
|
||||
_ => None,
|
||||
|
|
@ -112,7 +112,7 @@ impl LoroValue {
|
|||
}
|
||||
|
||||
#[inline]
|
||||
pub fn to_string(&self) -> Option<&SmString> {
|
||||
pub fn as_string(&self) -> Option<&SmString> {
|
||||
match self {
|
||||
LoroValue::String(s) => Some(s),
|
||||
_ => None,
|
||||
|
|
@ -120,7 +120,7 @@ impl LoroValue {
|
|||
}
|
||||
|
||||
#[inline]
|
||||
pub fn to_integer(&self) -> Option<i32> {
|
||||
pub fn as_integer(&self) -> Option<i32> {
|
||||
match self {
|
||||
LoroValue::Integer(i) => Some(*i),
|
||||
_ => None,
|
||||
|
|
@ -128,7 +128,7 @@ impl LoroValue {
|
|||
}
|
||||
|
||||
#[inline]
|
||||
pub fn to_double(&self) -> Option<f64> {
|
||||
pub fn as_double(&self) -> Option<f64> {
|
||||
match self {
|
||||
LoroValue::Double(d) => Some(*d),
|
||||
_ => None,
|
||||
|
|
@ -136,7 +136,7 @@ impl LoroValue {
|
|||
}
|
||||
|
||||
#[inline]
|
||||
pub fn to_bool(&self) -> Option<bool> {
|
||||
pub fn as_bool(&self) -> Option<bool> {
|
||||
match self {
|
||||
LoroValue::Bool(b) => Some(*b),
|
||||
_ => None,
|
||||
|
|
@ -144,7 +144,63 @@ impl LoroValue {
|
|||
}
|
||||
|
||||
#[inline]
|
||||
pub fn to_container(&self) -> Option<&ContainerID> {
|
||||
pub fn as_container(&self) -> Option<&ContainerID> {
|
||||
match self {
|
||||
LoroValue::Unresolved(c) => Some(c),
|
||||
_ => None,
|
||||
}
|
||||
}
|
||||
|
||||
#[inline]
|
||||
pub fn as_map_mut(&mut self) -> Option<&mut FxHashMap<InternalString, LoroValue>> {
|
||||
match self {
|
||||
LoroValue::Map(m) => Some(m),
|
||||
_ => None,
|
||||
}
|
||||
}
|
||||
|
||||
#[inline]
|
||||
pub fn as_list_mut(&mut self) -> Option<&mut Vec<LoroValue>> {
|
||||
match self {
|
||||
LoroValue::List(l) => Some(l),
|
||||
_ => None,
|
||||
}
|
||||
}
|
||||
|
||||
#[inline]
|
||||
pub fn as_string_mut(&mut self) -> Option<&mut SmString> {
|
||||
match self {
|
||||
LoroValue::String(s) => Some(s),
|
||||
_ => None,
|
||||
}
|
||||
}
|
||||
|
||||
#[inline]
|
||||
pub fn as_integer_mut(&mut self) -> Option<&mut i32> {
|
||||
match self {
|
||||
LoroValue::Integer(i) => Some(i),
|
||||
_ => None,
|
||||
}
|
||||
}
|
||||
|
||||
#[inline]
|
||||
pub fn as_double_mut(&mut self) -> Option<&mut f64> {
|
||||
match self {
|
||||
LoroValue::Double(d) => Some(d),
|
||||
_ => None,
|
||||
}
|
||||
}
|
||||
|
||||
#[inline]
|
||||
pub fn as_bool_mut(&mut self) -> Option<&mut bool> {
|
||||
match self {
|
||||
LoroValue::Bool(b) => Some(b),
|
||||
_ => None,
|
||||
}
|
||||
}
|
||||
|
||||
#[inline]
|
||||
pub fn as_container_mut(&mut self) -> Option<&mut ContainerID> {
|
||||
match self {
|
||||
LoroValue::Unresolved(c) => Some(c),
|
||||
_ => None,
|
||||
|
|
|
|||
|
|
@ -1,11 +1,225 @@
|
|||
use fxhash::FxHashMap;
|
||||
use std::{
|
||||
cmp::Ordering,
|
||||
collections::HashMap,
|
||||
ops::{Deref, DerefMut},
|
||||
};
|
||||
|
||||
use crate::{change::Lamport, ClientID};
|
||||
use fxhash::{FxBuildHasher, FxHashMap};
|
||||
use im::hashmap::HashMap as ImHashMap;
|
||||
|
||||
pub type VersionVector = FxHashMap<ClientID, u32>;
|
||||
use crate::{
|
||||
change::Lamport,
|
||||
id::{Counter, ID},
|
||||
span::IdSpan,
|
||||
ClientID,
|
||||
};
|
||||
|
||||
/// [VersionVector](https://en.wikipedia.org/wiki/Version_vector)
|
||||
///
|
||||
/// It's a map from [ClientID] to [Counter]. Its a right-open interval.
|
||||
/// i.e. a [VersionVector] of `{A: 1, B: 2}` means that A has 1 atomic op and B has 2 atomic ops,
|
||||
/// thus ID of `{client: A, counter: 1}` is out of the range.
|
||||
///
|
||||
/// In implementation, it's a immutable hash map with O(1) clone. Because
|
||||
/// - we want a cheap clone op on vv;
|
||||
/// - neighbor op's VersionVectors are very similar, most of the memory can be shared in
|
||||
/// immutable hashmap
|
||||
///
|
||||
/// see also [im].
|
||||
#[repr(transparent)]
|
||||
#[derive(Debug, PartialEq, Eq, Clone)]
|
||||
pub struct VersionVector(ImHashMap<ClientID, Counter>);
|
||||
|
||||
impl Deref for VersionVector {
|
||||
type Target = ImHashMap<ClientID, Counter>;
|
||||
|
||||
fn deref(&self) -> &Self::Target {
|
||||
&self.0
|
||||
}
|
||||
}
|
||||
|
||||
impl PartialOrd for VersionVector {
|
||||
fn partial_cmp(&self, other: &Self) -> Option<std::cmp::Ordering> {
|
||||
let mut self_greater = true;
|
||||
let mut other_greater = true;
|
||||
let mut eq = true;
|
||||
for (client_id, other_end) in other.iter() {
|
||||
if let Some(self_end) = self.get(client_id) {
|
||||
if self_end < other_end {
|
||||
self_greater = false;
|
||||
eq = false;
|
||||
}
|
||||
if self_end > other_end {
|
||||
other_greater = false;
|
||||
eq = false;
|
||||
}
|
||||
} else {
|
||||
self_greater = false;
|
||||
eq = false;
|
||||
}
|
||||
}
|
||||
|
||||
for (client_id, _) in self.iter() {
|
||||
if other.contains_key(client_id) {
|
||||
continue;
|
||||
} else {
|
||||
other_greater = false;
|
||||
eq = false;
|
||||
}
|
||||
}
|
||||
|
||||
if eq {
|
||||
Some(Ordering::Equal)
|
||||
} else if self_greater {
|
||||
Some(Ordering::Greater)
|
||||
} else if other_greater {
|
||||
Some(Ordering::Less)
|
||||
} else {
|
||||
None
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
impl DerefMut for VersionVector {
|
||||
fn deref_mut(&mut self) -> &mut Self::Target {
|
||||
&mut self.0
|
||||
}
|
||||
}
|
||||
|
||||
impl VersionVector {
|
||||
#[inline]
|
||||
pub fn new() -> Self {
|
||||
Self(ImHashMap::new())
|
||||
}
|
||||
|
||||
#[inline]
|
||||
pub fn set_end(&mut self, id: ID) {
|
||||
self.0.insert(id.client_id, id.counter + 1);
|
||||
}
|
||||
|
||||
/// update the end counter of the given client, if the end is greater
|
||||
/// return whether updated
|
||||
#[inline]
|
||||
pub fn try_update_end(&mut self, id: ID) -> bool {
|
||||
if let Some(end) = self.0.get_mut(&id.client_id) {
|
||||
if *end < id.counter + 1 {
|
||||
*end = id.counter + 1;
|
||||
true
|
||||
} else {
|
||||
false
|
||||
}
|
||||
} else {
|
||||
self.0.insert(id.client_id, id.counter + 1);
|
||||
true
|
||||
}
|
||||
}
|
||||
|
||||
pub fn get_missing_span(&self, target: &Self) -> Vec<IdSpan> {
|
||||
let mut ans = vec![];
|
||||
for (client_id, other_end) in target.iter() {
|
||||
if let Some(my_end) = self.get(client_id) {
|
||||
if my_end < other_end {
|
||||
ans.push(IdSpan::new(*client_id, *my_end, *other_end));
|
||||
}
|
||||
} else {
|
||||
ans.push(IdSpan::new(*client_id, 0, *other_end));
|
||||
}
|
||||
}
|
||||
|
||||
ans
|
||||
}
|
||||
|
||||
pub fn merge(&mut self, other: &Self) {
|
||||
for (&client_id, &other_end) in other.iter() {
|
||||
if let Some(my_end) = self.get_mut(&client_id) {
|
||||
if *my_end < other_end {
|
||||
*my_end = other_end;
|
||||
}
|
||||
} else {
|
||||
self.0.insert(client_id, other_end);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
pub fn includes(&mut self, id: ID) -> bool {
|
||||
if let Some(end) = self.get_mut(&id.client_id) {
|
||||
if *end > id.counter {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
false
|
||||
}
|
||||
}
|
||||
|
||||
impl Default for VersionVector {
|
||||
fn default() -> Self {
|
||||
Self::new()
|
||||
}
|
||||
}
|
||||
|
||||
impl From<FxHashMap<ClientID, Counter>> for VersionVector {
|
||||
fn from(map: FxHashMap<ClientID, Counter>) -> Self {
|
||||
let mut im_map = ImHashMap::new();
|
||||
for (client_id, counter) in map {
|
||||
im_map.insert(client_id, counter);
|
||||
}
|
||||
Self(im_map)
|
||||
}
|
||||
}
|
||||
|
||||
impl From<Vec<ID>> for VersionVector {
|
||||
fn from(vec: Vec<ID>) -> Self {
|
||||
let mut vv = VersionVector::new();
|
||||
for id in vec {
|
||||
vv.set_end(id);
|
||||
}
|
||||
|
||||
vv
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, PartialEq, Eq, Clone, Copy, PartialOrd, Ord)]
|
||||
pub(crate) struct TotalOrderStamp {
|
||||
pub(crate) lamport: Lamport,
|
||||
pub(crate) client_id: ClientID,
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod tests {
|
||||
use super::*;
|
||||
mod cmp {
|
||||
use super::*;
|
||||
#[test]
|
||||
fn test() {
|
||||
let a: VersionVector = vec![ID::new(1, 1), ID::new(2, 2)].into();
|
||||
let b: VersionVector = vec![ID::new(1, 1), ID::new(2, 2)].into();
|
||||
assert_eq!(a.partial_cmp(&b), Some(Ordering::Equal));
|
||||
|
||||
let a: VersionVector = vec![ID::new(1, 2), ID::new(2, 1)].into();
|
||||
let b: VersionVector = vec![ID::new(1, 1), ID::new(2, 2)].into();
|
||||
assert_eq!(a.partial_cmp(&b), None);
|
||||
|
||||
let a: VersionVector = vec![ID::new(1, 2), ID::new(2, 3)].into();
|
||||
let b: VersionVector = vec![ID::new(1, 1), ID::new(2, 2)].into();
|
||||
assert_eq!(a.partial_cmp(&b), Some(Ordering::Greater));
|
||||
|
||||
let a: VersionVector = vec![ID::new(1, 0), ID::new(2, 2)].into();
|
||||
let b: VersionVector = vec![ID::new(1, 1), ID::new(2, 2)].into();
|
||||
assert_eq!(a.partial_cmp(&b), Some(Ordering::Less));
|
||||
}
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn im() {
|
||||
let mut a = VersionVector::new();
|
||||
a.set_end(ID::new(1, 1));
|
||||
a.set_end(ID::new(2, 1));
|
||||
let mut b = a.clone();
|
||||
b.merge(&vec![ID::new(1, 2), ID::new(2, 2)].into());
|
||||
assert!(a != b);
|
||||
assert_eq!(a.get(&1), Some(&2));
|
||||
assert_eq!(a.get(&2), Some(&2));
|
||||
assert_eq!(b.get(&1), Some(&3));
|
||||
assert_eq!(b.get(&2), Some(&3));
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -11,3 +11,6 @@ loro-core = {path = "../loro-core"}
|
|||
ring = "0.16.20"
|
||||
rle = {path = "../rle"}
|
||||
sha2 = "0.10.2"
|
||||
|
||||
[lib]
|
||||
doctest = false
|
||||
|
|
|
|||
|
|
@ -1,5 +1,8 @@
|
|||
use fxhash::FxHashMap;
|
||||
use loro_core::{id::ClientID, version::VersionVector};
|
||||
use loro_core::{
|
||||
id::{ClientID, Counter},
|
||||
version::VersionVector,
|
||||
};
|
||||
use rle::RleVec;
|
||||
|
||||
use crate::raw_change::{ChangeData, ChangeHash};
|
||||
|
|
@ -72,9 +75,9 @@ impl RawStore {
|
|||
}
|
||||
|
||||
pub fn version_vector(&self) -> VersionVector {
|
||||
let mut version_vector = FxHashMap::default();
|
||||
let mut version_vector = VersionVector::new();
|
||||
for (client_id, changes) in &self.changes {
|
||||
version_vector.insert(*client_id, changes.len() as u32);
|
||||
version_vector.insert(*client_id, changes.len() as Counter);
|
||||
}
|
||||
|
||||
version_vector
|
||||
|
|
|
|||
|
|
@ -6,3 +6,4 @@ edition = "2021"
|
|||
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
|
||||
|
||||
[dependencies]
|
||||
num = "0.4.0"
|
||||
|
|
|
|||
|
|
@ -1,2 +1,24 @@
|
|||
mod rle;
|
||||
pub use crate::rle::{HasLength, Mergable, RleVec, SearchResult, Slice, SliceIterator, Sliceable};
|
||||
//! Run length encoding library.
|
||||
//!
|
||||
//! There are many mergeable types. By merging them together we can get a more compact representation of the data.
|
||||
//! For example, in many cases, `[0..5, 5..10]` can be merged into `0..10`.
|
||||
//!
|
||||
//! # RleVec
|
||||
//!
|
||||
//! RleVec<T> is a vector that can be compressed using run-length encoding.
|
||||
//!
|
||||
//! A T value may be merged with its neighbors. When we push new element, the new value
|
||||
//! may be merged with the last element in the array. Each value has a length, so there
|
||||
//! are two types of indexes:
|
||||
//! 1. (merged) It refers to the index of the merged element.
|
||||
//! 2. (atom) The index of substantial elements. It refers to the index of the atom element.
|
||||
//!
|
||||
//! By default, we use atom index in RleVec.
|
||||
//! - len() returns the number of atom elements in the array.
|
||||
//! - get(index) returns the atom element at the index.
|
||||
//! - slice(from, to) returns a slice of atom elements from the index from to the index to.
|
||||
//!
|
||||
mod rle_trait;
|
||||
mod rle_vec;
|
||||
pub use crate::rle_trait::{HasLength, Mergable, Rle, Slice, Sliceable};
|
||||
pub use crate::rle_vec::{RleVec, SearchResult, SliceIterator};
|
||||
|
|
|
|||
44
crates/rle/src/rle_trait.rs
Normal file
44
crates/rle/src/rle_trait.rs
Normal file
|
|
@ -0,0 +1,44 @@
|
|||
pub trait Mergable<Cfg = ()> {
|
||||
fn is_mergable(&self, _other: &Self, _conf: &Cfg) -> bool
|
||||
where
|
||||
Self: Sized,
|
||||
{
|
||||
false
|
||||
}
|
||||
|
||||
fn merge(&mut self, _other: &Self, _conf: &Cfg)
|
||||
where
|
||||
Self: Sized,
|
||||
{
|
||||
unreachable!()
|
||||
}
|
||||
}
|
||||
|
||||
pub trait Sliceable {
|
||||
fn slice(&self, from: usize, to: usize) -> Self;
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone, Copy)]
|
||||
pub struct Slice<'a, T> {
|
||||
pub value: &'a T,
|
||||
pub start: usize,
|
||||
pub end: usize,
|
||||
}
|
||||
|
||||
impl<T: Sliceable> Slice<'_, T> {
|
||||
pub fn into_inner(&self) -> T {
|
||||
self.value.slice(self.start, self.end)
|
||||
}
|
||||
}
|
||||
|
||||
pub trait HasLength {
|
||||
fn is_empty(&self) -> bool {
|
||||
self.len() == 0
|
||||
}
|
||||
|
||||
fn len(&self) -> usize;
|
||||
}
|
||||
|
||||
pub trait Rle<Cfg = ()>: HasLength + Sliceable + Mergable<Cfg> {}
|
||||
|
||||
impl<T: HasLength + Sliceable + Mergable<Cfg>, Cfg> Rle<Cfg> for T {}
|
||||
|
|
@ -1,4 +1,7 @@
|
|||
use std::ops::Range;
|
||||
use num::{cast, Integer, NumCast};
|
||||
use std::ops::{Range, Sub};
|
||||
|
||||
use crate::{HasLength, Mergable, Rle, Slice, Sliceable};
|
||||
|
||||
/// RleVec<T> is a vector that can be compressed using run-length encoding.
|
||||
///
|
||||
|
|
@ -20,40 +23,6 @@ pub struct RleVec<T, Cfg = ()> {
|
|||
cfg: Cfg,
|
||||
}
|
||||
|
||||
pub trait Mergable<Cfg = ()> {
|
||||
fn is_mergable(&self, _other: &Self, _conf: &Cfg) -> bool
|
||||
where
|
||||
Self: Sized,
|
||||
{
|
||||
false
|
||||
}
|
||||
|
||||
fn merge(&mut self, _other: &Self, _conf: &Cfg)
|
||||
where
|
||||
Self: Sized,
|
||||
{
|
||||
unreachable!()
|
||||
}
|
||||
}
|
||||
|
||||
pub trait Sliceable {
|
||||
fn slice(&self, from: usize, to: usize) -> Self;
|
||||
}
|
||||
|
||||
impl<T: Sliceable> Slice<'_, T> {
|
||||
pub fn into_inner(&self) -> T {
|
||||
self.value.slice(self.start, self.end)
|
||||
}
|
||||
}
|
||||
|
||||
pub trait HasLength {
|
||||
fn is_empty(&self) -> bool {
|
||||
self.len() == 0
|
||||
}
|
||||
|
||||
fn len(&self) -> usize;
|
||||
}
|
||||
|
||||
pub struct SearchResult<'a, T> {
|
||||
pub element: &'a T,
|
||||
pub merged_index: usize,
|
||||
|
|
@ -253,13 +222,6 @@ pub struct SliceIterator<'a, T> {
|
|||
end_offset: usize,
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone, Copy)]
|
||||
pub struct Slice<'a, T> {
|
||||
pub value: &'a T,
|
||||
pub start: usize,
|
||||
pub end: usize,
|
||||
}
|
||||
|
||||
impl<'a, T: HasLength> Iterator for SliceIterator<'a, T> {
|
||||
type Item = Slice<'a, T>;
|
||||
|
||||
|
|
@ -316,6 +278,31 @@ impl<T> HasLength for RleVec<T> {
|
|||
}
|
||||
}
|
||||
|
||||
impl<T: Integer + NumCast + Copy> Sliceable for Range<T> {
|
||||
fn slice(&self, start: usize, end: usize) -> Self {
|
||||
self.start + cast(start).unwrap()..self.start + cast(end).unwrap()
|
||||
}
|
||||
}
|
||||
|
||||
impl<T: PartialOrd<T> + Copy> Mergable for Range<T> {
|
||||
fn is_mergable(&self, other: &Self, _: &()) -> bool {
|
||||
other.start <= self.end && other.start >= self.start
|
||||
}
|
||||
|
||||
fn merge(&mut self, other: &Self, _conf: &())
|
||||
where
|
||||
Self: Sized,
|
||||
{
|
||||
self.end = other.end;
|
||||
}
|
||||
}
|
||||
|
||||
impl<T: num::Integer + NumCast + Copy> HasLength for Range<T> {
|
||||
fn len(&self) -> usize {
|
||||
cast(self.end - self.start).unwrap()
|
||||
}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod test {
|
||||
mod prime_value {
|
||||
|
|
@ -1 +1 @@
|
|||
nightly
|
||||
stable
|
||||
|
|
|
|||
Loading…
Reference in a new issue