This adds an initial `jj util gc` command, which simply calls `git gc`
when using the Git backend. That should already be useful in
non-colocated repos because it's not obvious how to GC (repack) such
repos. In my own jj repo, it shrunk `.jj/repo/store/` from 2.4 GiB to
780 MiB, and `jj log --ignore-working-copy` was sped up from 157 ms to
86 ms.
I haven't added any tests because the functionality depends on having
`git` binary on the PATH, which we don't yet depend on anywhere
else. I think we'll still be able to test much of the future parts of
garbage collection without a `git` binary because the interesting
parts are about manipulating the Git repo before calling `git gc` on
it.
I think this is a variant of the problem fixed by 7fda80fc22 "tree: simplify
conflict before resolving at hunk level." We need to simplify() the conflict
before and after extracting file ids because the source conflict values may
contain trees to be cancelled out, and the file values may differ only in exec
bits. Since the legacy tree passes a simplified conflict in to this function,
I made the merged tree do the same.
Fixes#2654
Allowing `jj init --git` in an existing Git repo creates a second Git
store in `.jj/repo/store/git`, totally disconnected from the existing
Git store. This will only produce extremely confusing bugs for users,
since any operations they make in Git will *not* be reflected in the
jj repo.
Per discussion in https://github.com/martinvonz/jj/discussions/2555. I'm
okay with either way, but it's confusing if we had "branch create" and
"branch set" and both of these could create a new branch.
As discussed in Discord, it's less useful if remote_branches() included
Git-tracking branches. Users wouldn't consider the backing Git repo as
a remote.
We could allow explicit 'remote_branches(remote=exact:"git")' query by changing
the default remote pattern to something like 'remote=~exact:"git"'. I don't
know which will be better overall, but we don't have support for negative
patterns anyway.
Summary: A natural extension of the existing support, as suggested by Scott
Olson. Closes#2496.
Signed-off-by: Austin Seipp <aseipp@pobox.com>
Change-Id: I91c9c8c377ad67ccde7945ed41af6c79
Like "jj log PATHS...", unmatched name isn't an error. I don't think
"jj branch list glob:'push-*'" should fail just because there are no in-flight
PR branches.
Since "jj git fetch --branch" supports glob patterns, users would expect that
"jj git push --branch glob:.." also works.
The error handling bits are copied from "branch" sub commands. We might want to
extract it to a common helper function, but I haven't figured out a reasonable
boundary point yet.
AFAICT, all callers of `Merge::to_file_merge()` are already well
prepared for working with executable files. It's called from these
places:
* `local_working_copy.rs`: Materialized conflicts are correctly
updated using `Merge::with_new_file_ids()`.
* `merge_tools/`: Same as above.
* `cmd_cat()`: We already ignore the executable bit when we print
non-conflicted files, so it makes sense to also ignore it for
conflicted files.
* `git_diff_part()`: We print all conflicts with mode "100644" (the
mode for regular files). Maybe it's best to use "100755" for
conflicts that are unambiguously executable, or maybe it's better to
use a fake mode like "000000" for all conflicts. Either way, the
current behavior seems fine.
* `diff_content()`: We use the diff content in various diff
formats. We could add more detail about the executable bits in some
of them, but I think the current output is fine. For example,
instead of our current "Created conflict in my-file", we could say
"Created conflict in executable file my-file" or "Created conflict
in ambiguously executable file my-file". That's getting verbose,
though.
So, I think all we need to do is to make `Merge::to_file_merge()` not
require its inputs to be non-executable.
Closes#1279.
The parse rule is lax compared to revset. We could require the pattern to be
quoted, but that would mean glob patterns have to be quoted like 'glob:"foo*"'.
I personally don't mind if "jj branch list" showed all non-tracking branches,
but I agree it would be a mess if ~500 remote branches were listed. So let's
hide them by default as non-tracking branches aren't so interesting.
Closes#1136
We can provide more actionable error message than "not fast-forwardable". If
the push was fast-forwardable, "jj branch track" should be able to merge the
remote branch without conflicts, so the added step would be minimal.
This means that the commits previously pinned by remote branches are no longer
abandoned. I think that's more correct since "push" is the operation to
propagate local view to remote, and uninteresting commits should have been
locally abandoned.
This patch adds MutableRepo::track_remote_branch() as we'll probably need to
track the default branch on "jj git clone". untrack_remote_branch() is also
added for consistency.
Summary: This allows `workspace forget` to forget multiple workspaces in a
single action; it now behaves more consistently with other verbs like `abandon`
which can take multiple revisions at one time.
There's some hoop-jumping involved to ensure the oplog transaction description
looks nice, but as they say: small conveniences cost a lot.
Signed-off-by: Austin Seipp <aseipp@pobox.com>
Change-Id: Id91da269f87b145010c870b7dc043748
Summary: Workspaces are most useful to test different versions (commits) of
the tree within the same repository, but in many cases you want to check out a
specific commit within a workspace.
Make that trivial with a `--revision` option which will be used as the basis
for the new workspace. If no `-r` option is given, then the previous behavior
applies: the workspace is created with a working copy commit created on top of
the current working copy commit's parent.
Signed-off-by: Austin Seipp <aseipp@pobox.com>
Change-Id: I23549efe29bc23fb9f75437b6023c237
Before this patch, when updating to a commit that has a file that's
currently an ignored file on disk, jj would crash. After this patch,
we instead leave the conflicting files or directories on disk. We
print a helpful message about how to inspect the differences between
the intended working copy and the actual working copy, and how to
discard the unintended changes.
Closes#976.
I've added a boolean flag to the store to ensure that the migration never runs
more than once after the view gets "op restore"-d. I'll probably reorganize the
branches structure to support non-tracking branches later, but updating the
storage format in a single commit would be too involved.
If jj is downgraded, these "git" remote refs would be exported to the Git repo.
Users might have to remove them manually.
I have used the tree-level conflict format for several weeks without
problem (after the fix in 51b5d168ae). Now - right after the 0.10.0
release - seems like a good time to enable the config by default.
I enabled the config in our default configs in the CLI crate to reduce
impact on tests (compared to changing the default in `settings.rs`).
`jj split` with no arguments operates interactively, but I am nonetheless constantly running `jj split -i` because I expect an `--interactive` flag to exist for consistency.
However, `jj split <paths>` before this commit always operates non-interactively, so this commit has the nice practical effect that you can restrict your interactive splitting to a certain set of paths.
This adds a new `revset-aliases.immutable_heads()s` config for
defining the set of immutable commits. The set is defined as the
configured revset, as well as its ancestors, and the root commit
commit (even if the configured set is empty).
This patch also adds enforcement of the config where we already had
checks preventing rewrite of the root commit. The working-copy commit
is implicitly assumed to be writable in most cases. Specifically, we
won't prevent amending the working copy even if the user includes it
in the config but we do prevent `jj edit @` in that case. That seems
good enough to me. Maybe we should emit a warning when the working
copy is in the set of immutable commits.
Maybe we should add support for something more like [Mercurial's
phases](https://wiki.mercurial-scm.org/Phases), which is propagated on
push and pull. There's already some affordance for that in the view
object's `public_heads` field. However, this is simpler, especially
since we can't propagate the phase to Git remotes, and seems like a
good start. Also, it lets you say that commits authored by other users
are immutable, for example.
For now, the functionality is in the CLI library. I'm not sure if we
want to move it into the library crate. I'm leaning towards letting
library users do whatever they want without being restricted by
immutable commits. I do think we should move the functionality into a
future `ui-lib` or `ui-util` crate. That crate would have most of the
functionality in the current `cli_util` module (but in a
non-CLI-specific form).
I think the feature is requested by enough users that we should
include it by default, also for people who install from source (we
include it in the `packaging` feature already).
It increases the size of the binary from 16.5 MiB to 17.8 MiB. I
suspect we'd see some of that increase in size soon anyway, as I'm
probably going to use Tokio for making async backend requests.
Since e7e49527ef "git: ensure that remote branches never diverge", the last
known "refs/remotes" ref should be synced with the corresponding remote branch.
So we can always trust the branch@remote expression. We don't need "refs/tags"
lookup either since tags should have been imported by git::import_refs().
FWIW, I'm thinking of reorganizing view.git_refs() map as per-remote views.
It would be nice if we can get rid of revsets and template keywords exposing
low-level Git ref primitives.
This is a naive implementation, which cannot deal with multiple children
or parents stemming from merges.
Note: I gave each command separate a separate argument struct
for extensibility.
Fixes#878
Suppose "x::y" is the operator that defaults to "root()::visible_heads()"
respectively, "::" is identical to "all()". Since we've just changed the
behavior of "..y", ".." is now "root()..visible_heads()" meaning "~root()".
This patch also extracts format_detailed_signature() function to deduplicate
the "show" template bits.
The added placeholder templates aren't labeled as "empty". If needed, I think
the whole template can be labeled as "empty" (or "empty_commit") just like
"working_copy".
Closes#2112
This is what I proposed in #2095. @ is now an operator to concatenate symbols.
Unlike the other operators, lhs/rhs of @ is not a target of alias substitution.
'x' in 'x@y' doesn't look like a named variable, though it's technically
possible to allow definition of an alias expanded to a symbol of specific remote
or vice versa. This will probably apply to the kind:pattern syntax, where
aliases are expanded due to the current implementation restriction. I've added
a TODO comment about that.
The way `jj git push` without arguments chooses branches pointing to
either `@` or `@-` is unusual and difficult to explain. Now that we
have `-r`, we could instead default it to `-r '@-::@'`. However, I
think it seems likely that users will want to push all local branches
leading up to `@` from the closest remote branch. That's typically
what I want. This patch changes the default to do that.
We resolve file paths into repo-relative paths while parsing the
revset expression, so I think it's consistent to also resolve which
workspace "@" refers to while parsing it. That means we won't need the
workspace context both while parsing and while resolving symbols.
In order to break things like `author("martinvonz@")` (thanks to @yuja
for catching this), I also changed the parsing of working-copy
expressions so they are not allowed to be
quoted. `author(martinvonz@)` will therefore be an error now. That
seems like a small improvement anyway, since we have recently talked
about making `root` and `[workspace]@` not parsed as other symbols.
Per discussion in #2107, I believe "exact" is preferred.
We can also change the default to exact match, but it doesn't always make
sense. Exact match would be useful for branches(), but not for description().
We could define default per predicate function, but I'm pretty sure I cannot
remember which one is which.
This commit replaces the functions `UserSettings::user_name_placeholder()`` and
`UserSettings::user_email_placeholder()` with `const` `&str`s to emphasize that
the placeholder strings must not be changed to support commits without
names or email addresses made before this change.
The syntax is slightly different from Mercurial. In Mercurial, a pattern must
be quoted like "<kind>:<needle>". In JJ, <kind> is a separate parsing node, and
it must not appear in a quoted string. This allows us to report unknown prefix
as an error.
There's another subtle behavior difference. In Mercurial, branch(unknown) is
an error, whereas our branches(literal:unknown) is resolved to an empty set.
I think erroring out doesn't make sense for JJ since branches() by default
performs substring matching, so its behavior is more like a filter.
The parser abuses DAG range syntax for now. It can be rewritten once we remove
the deprecated x:y range syntax.
One use case for `jj split` is when creating a new commit from some of
the changes in the working copy. If there's no description on the
working-copy commit in that case, it seems better to not ask the user
to provide one when they're splitting the commit either.
I've extracted the `builtin_log_root` template for users to customize the
default templates without fully overriding them, for example I would remove
the change_id/commit_id for myself - and we discussed in Discord that leaving
those makes sense for the user to be reminded/teached that the root commit has
a change id made from z's.
Similar to other boolean flags, such as "working_copy" or "empty".
We could test something like
`"0000000000000000000000000000000000000000".contains(commit_id)`
like I did for myself, but first of all this is ugly, and secondly the root
commit id is not guaranteed to be 40 zeroes as custom backend implementations
could have some other root.
That is, jj will use ui.default_description as a starting point when
user is about to describe an empty change.
I think it might be confusing to do this with -m / --stdin (violates
WYSIWYG), so I'm only doing this when jj invokes an editor.
Also, this could evolve into a proper template in the future instead of
just plain text, to allow inheriting from parent change(s), for example.
Partially addresses #1354.
Maybe we could load GitBackend without resolving .git symlink, but that would
introduce more subtle bugs. Instead, we calculate the expected Git workdir path
from the canonical ".git" path.
Fixes#2011
This makes it possible to use ed25519 and ed25519-sk keys by trying
them one at a time. However, it still fails if one of them is
password-protected; we don't try the next key in that case.
As reported in #1970, SSH authentication would sometimes run into a
loop where it repeatedly tries to use ssh-agent for authentication
without making progess. The problem can be reproduced by simply
removing `$SSH_AUTH_KEY` from your environment (and not having a Git
credentials helper configured, I think).
This seems to be a bug introduced by b104f8e154c21. That commit meant
to make it so we attempt to use ssh-agent and fall back to using
(password-less) keys after that. The problem is that
`git2::Cred::ssh_key_from_agent()` just returns an object that will be
used later for looking up the credentials from ssh-agent, so the call
will not fail because ssh-agent is not reachable.
This commit attempts to fix the problem by having the credentials
callback attempt to use ssh-agent only once.
This is basic implementation. There's no config knob to enable the external
diff command by default. It reuses the merge-tools table because that's how
external diff/merge commands are currently configured. We might want to
reorganize them in #1285.
If you run "jj diff --tool meld", GUI diff will open and jj will wait for
meld to quit. This also applies to "jj log -p". The "diff --tool gui" behavior
is somewhat useful, but "log -p --tool gui" wouldn't. We might want some flag
to mark the tool output can't be streamed.
Another thing to consider is tools that can't generate directory diffs. Git
executes ext-diff tool per file, but we don't. Difftastic can compare
directories, and doing that should be more efficient since diffs can be
computed in parallel (at the expense of unsorted output.)
Closes#1886
This adds the new --colocate flag to `jj git clone`.
```
jj git clone --colocate https://github.com/foo/bar
```
is effectively equivalent to:
```
git clone https://github.com/foo/bar
cd bar
jj init --git-repo=.
```
The `--allow-large-revset` option for `jj rebase` and `jj new` is used
for allowing a single revset to resolve to more than one destination
commit. It also means that duplicate commits between individual
revsets are allowed (e.g. `jj rebase -d x -d 'x|y'`). I'm about to
replace the first meaning of the flag by a revset function. I don't
think it's worth keeping the flag only for the second meaning, so I'm
just removing the feature instead. We can add it back under a
different name (`--allow-duplicate-destinations`?) if people care
about it.
The `--allow-large-revsets` flag we have on `jj rebase` and `jj new`
allows the user to do e.g. `jj rebase --allow-large-revsets -b
main.. -d main` to rebase all commits that are not in main onto
main. The reason we don't allow these revsets to resolve to multiple
commits by default is that we think users might specify multiple
commits by mistake. That's probably not much of a problem with `jj
rebase -b` (maybe we should always allow that to resolve to multiple
commits), but the user might want to know if `jj rebase -d @-`
resolves to multiple commits.
One problem with having a flag to allow multiple commits is that it
needs to be added to every command where we want to allow multiple
commits but default to one. Also, it should probably apply to each
revset argument those commands take. For example, even if the user
meant `-b main..` to resolve to multiple commits, they might not have
meant `-d main` to resolve to multiple commits (which it will in case
of a conflicted branch), so we might want separate
`--allow-large-revsets-in-destination` and
`--allow-large-revsets-in-source`, which gets quite cumbersome. It
seems better to have some syntax in the individual revsets for saying
that multiple commits are allowed.
One proposal I had was to use a `multiple()` revset function which
would have no effect in general but would be used as a marker if used
at the top level (e.g. `jj rebase -d 'multiple(@-)'`). After some
discussion on the PR adding that function (#1911), it seems that the
consensus is to instead use a prefix like `many:` or `all:`. That
avoids the problem with having a function that has no effect unless
it's used at the top level (`jj rebase -d 'multiple(x)|y'` would have
no effect).
Since we already have the `:` operator for DAG ranges, we need to
change it to make room for `many:`/`all:` syntax. This commit starts
that by allowing both `:` and `::`.
I have tried to update the documentation in this commit to either
mention both forms, or just the new and preferred `::` form. However,
it's useless to search for `:` in Rust code, so I'm sure I've missed
many instances. We'll have to address those as we notice them. I'll
let most tests use `:` until we deprecate it or delete it.
This is breaking change. Old jj binary will panic if it sees a view saved by
new jj. Alternatively, we can store both new and legacy data for backward
compatibility.
The original idea was similar to Mercurial's "topo" sorting, but it was bad
at handling merge-heavy history. In order to render merges of topic branches
nicely, we need to prioritize branches at merge point, not at fork point.
OTOH, we do also want to place unmerged branches as close to the fork point
as possible. This commit implements the former requirement, and the latter
will be addressed by the next commit.
I think this is similar to Git's sorting logic described in the following blog
post. In our case, the in-degree walk can be dumb since topological order is
guaranteed by the index. We keep HashSet<CommitId> instead of an in-degree
integer value, which will be used in the next commit to resolve new heads as
late as possible.
https://github.blog/2022-08-30-gits-database-internals-ii-commit-history-queries/#topological-sorting
Compared to Sapling's beautify_graph(), this is lazy, and can roughly preserve
the index (or chronological) order. I tried beautify_graph() with prioritizing
the @ commit, but the result seemed too aggressively reordered. Perhaps, for
more complex history, beautify_graph() would produce a better result. For my
wip branches (~30 branches, a couple of commits per branch), this works pretty
well.
#242
Summary: Let's be more aggressive about tracking the latest stable Rust release.
There's little benefit to being conservative so early on, especially when no
users seem to have faced any issue with upgrading, or strictly required an old
Rust version.
Right now, just lagging Rust by 1 major release probably seems fine. We're
targeting 1.71.0 to get ahead of the curve, since 1.72.0 will likely release
sometime before the next `jj` release.
Signed-off-by: Austin Seipp <aseipp@pobox.com>
Change-Id: I4e691b6ba63b5b9023a75ae0a6917672
@mlcui-google made their first contribution after I drafted the
release notes for 0.8.0 and I forgot to update the release notes
before merging the PR.
Almost everyone calls the project "jj", and there seeems to be
consensus that we should rename the crates. I originally wanted the
crates to be called `jj` and `jj-lib`, but `jj` was already
taken. `jj-cli` is probably at least as good for it anyway.
Once we've published a 0.8.0 under the new names, we'll release 0.7.1
versions under the old names with pointers to the new crates names.
Typical query would be something like -r 'mine()' or -r 'branches()' to
exclude remote-only branches #1136.
The query matches against local targets only. This means there's no way to
select deleted/forgotten branches by -r option. If we add a default revset
configuration, we'll need some way to turn the default off.
The motivating use-case was this `jj signoff` script: https://gist.github.com/thoughtpolice/8f2fd36ae17cd11b8e7bd93a70e31ad6
Which includes lines like this:
```sh
NAME=$(jj config list user.name | awk '{split($0, a, "="); print a[2];}' | tr -d '"')
MAIL=$(jj config list user.email | awk '{split($0, a, "="); print a[2];}' | tr -d '"')
```
There is no reason that we should have to clumsily parse out the config values. This `jj config get` command supports scripting use-cases like this.
Use `br@git` instead.
Before, if there is not a local branch `br`, jj tried to resolve
it as a git ref `refs/heads/br`. Unchanged from before, `br` can
still be resolved as a tag `refs/tag/br`.
This doesn't change the way @git branches are stored in `git_refs` as opposed
to inside `BranchTarget` like normal remote-tracking branches. There are
subtle differences in behavior with e.g. `jj branch forget` and I'm not sure
how easy it is to rewrite `jj git import/export` to support a different
way of storage.
I've decided to call these "local-git tracking branches" since they track
branches in the local git repository. "local git-tracking" branches sounds a
bit more natural, but these could be confused with there are no remote
git-tracking branches. If one had the idea these might exist, they would be
confused with remote-tracking branches in the local git repo.
This addresses a portion of #1666
I think I will find this useful in at least two cases:
1. When you already have a branch pointing to some commit, it's easier
to do `jj git push -r xyz` than `jj git push --branch
push-xyzxyzyxzxyz`.
2. When you have a stack of changes, it's useful to be able to push
all of them at once.
I think we should also update the default behavior of `jj git push` to
be `jj git push -r 'remote_branches()..@'` or something like
that. That removes the ugliness of having a default behavior that the
user can't reproduce using flags. I'll leave that change for a
separate PR.
This was pretty simple. I simplified a bit by making the transaction
description mention only branches, not changes. It still mentions the
branches created for the changes, however. Also, since the operation
"tags" contain the full command line, I think it'll still be
relatively easy for the user to understand what the operation was
about.
Currently, if the user modifies a modify/delete conflict, we always
consider the result resolved. That happens because we materialize the
missing side of the conflict as an empty string but when we parse the
conflict, we expect only the number of sides in the input
conflict. For example, if the input is a regular modify/delete
conflict with one remove and one add, the materialized markers will
have one remove and two adds (one of them empty), but when we try to
parse it, we expect one remove and only one add. When we fail to parse
it, we consider it resolved.
This commit fixes the bug by using
`conflicts::Conflict<Option<TreeValue>>` and keeping track of which
sides were supposed to be empty. We could have fixed the bug without
switching to `conflicts::Conflict`, but we want to switch anyway, and
the fix happens naturally when switching.
`jj sparse` is a bit different from other commands in that its `jj
sparse --list` is practically a separate command. Let's make it an
actual subcommand for consistency, and so we can more cleanly add
additional flags for `jj sparse list` in the future. I moved all the
other arguments to `jj sparse set`. I'm not sure if `jj sparse set
--reset` would have been better as `jj sparse reset`, but it is
technically just updating the sparse patterns just like the other
arguments (`--clear`, `--add` , `--remove`).
This bug concerns the way `import_refs` that gets called by `fetch` computes
the heads that should be visible after the import.
Previously, the list of such heads was computed *before* local branches were
updated based on changes to the remote branches. So, commits that should have
been abandoned based on this update of the local branches weren't properly
abandoned.
Now, `import_refs` tracks the heads that need to be visible because of some ref
in a mapping keyed by the ref. If the ref moves or is deleted, the
corresponding heads are updated.
Fixes#864
This adds a config called `revsets.short-prefixes`, which lets the
user specify a revset in which to disambiguate otherwise ambiguous
change/commit ids. It defaults to the value of `revsets.log`.
I made it so you can disable the feature by setting
`revsets.short-prefixes = ""`. I don't like that the default value
(using `revsets.log`) cannot be configured explicitly by the
user. That will be addressed if we decide to merge the `[revsets]` and
`[revset-aliases]` sections some day.
I plan to add `revsets.short-prefixes` and `revsets.immutable` soon,
and I think `[revsets]` seems like reasonable place to put them. It
seems consistent with our `[templates]` section. However, it also
suffers from the same problem as that section, which is that the
difference between `[templates]` and `[template-aliases]` is not
clear. We can decide about about templates and revsets later.
The current behavior was introduced by 20eb9ecec1 "git: don't abandon
HEAD commit when it loses a branch." While the change made HEAD mutation
behavior more consistent with a plain ref operation, HEAD can also move on
checkout, and checkout shouldn't be considered a history rewriting operation.
I'm not saying the new behavior is always correct, but I think it's safer
than losing old HEAD branch. I also think this change will help if we want
to extract HEAD management function from git::import_refs().
Fixes#1042.
Establishing a unique file extension for the temporary files created
via `jj describe` helps to ensure that text editors can recognize the
filetype and alter settings accordingly. This will open the door for
an improved user experience, and allow for setting things like the
appropriate text-width/rulers, syntax highlighting of the diff summary
(see Git's commit tree-sitter grammer [1]), easy toggling of the `JJ:`
comment lines, etc.
I examined the behavior of filetype detection across a number of
common text editors, and the most universally-support mechanism was
to have a unique extension that does not include any periods. Meaning
that namespacing via something like `.jj.txt` instead, won't always be
detected due to inconsistent matching prioritization across editors.
It also makes sense to assume that we may want other Jujutsu-specific
filetypes in the future.
The filename prefix has also been switched to be `editor-` for clarity,
as well as to ease matching a glob-pattern if we ever need to garbage
collect leftover tempfiles. This structure is similar to what Mercurial
and Sapling do as well.
[1] https://github.com/the-mikedavis/tree-sitter-git-commit
This is a convenience optimization to improve the default user
experience, since `jj log` is a frequently run command. Accessing the
help information explicitly still follows normal CLI conventions, and
instructions are displayed appropriately if the user happens to make a
mistake. Discoverability should not be adversely harmed.
Note that this behavior mirrors what Sapling does [2], where `sl` will
display the smartlog by default.
[1] https://github.com/clap-rs/clap/issues/975
[2] https://sapling-scm.com/docs/overview/smartlog
I wasn't quite happy with `jj support` but I couldn't think of
anything better when I moved the commands from `jj debug` in
e2b4d7058d. Thanks to @ilyagr for suggesting `jj util`.
The `heads()` revset function with one argument is the counterpart to
`roots()`. Without arguments, it returns the visible heads in the
repo, i.e. `heads(all())`. The two use cases are quite different, and
I think it would be good to clarify that the no-arg form returns the
visible heads, so let's split that out to a new `visible_heads()`
function.
This serves the role of limit() in Mercurial. Since revsets in JJ is
(conceptually) an unordered set, a "limit" predicate should define its
ordering criteria. That's why the added predicate is named as "latest".
Closes#1110
I think requests to reset the author came up twice in the last week,
so let's just add support for it. I copied git's behavior of resetting
the name, email, and timestamp. The flag name is also from git.
We need 1.64 to bump `clap` to `4.1`. We don't really need to upgrade
to that, but being on an older version causes minor confusions like
#1393. Rust 1.64 is very close to 6 months old at this point.
The `jj debug` commands are hidden from help and are described as
"Low-level commands not intended for users", but e.g. `jj debug
completion` is intended for users, and should be visible in the help
output.
By using one letter for the path type before and one letter for path
type after, we can encode much more information than just the current
'M'/'A'/'R'. In particular, we can indicate new and resolved
conflicts. The color still encodes the same information as before. The
output looks a bit weird after many years of using `hg status`. It's a
bit more similar to the `git status -s` format with one letter for the
index and one with the working copy. Will we get used to it and find
it useful?
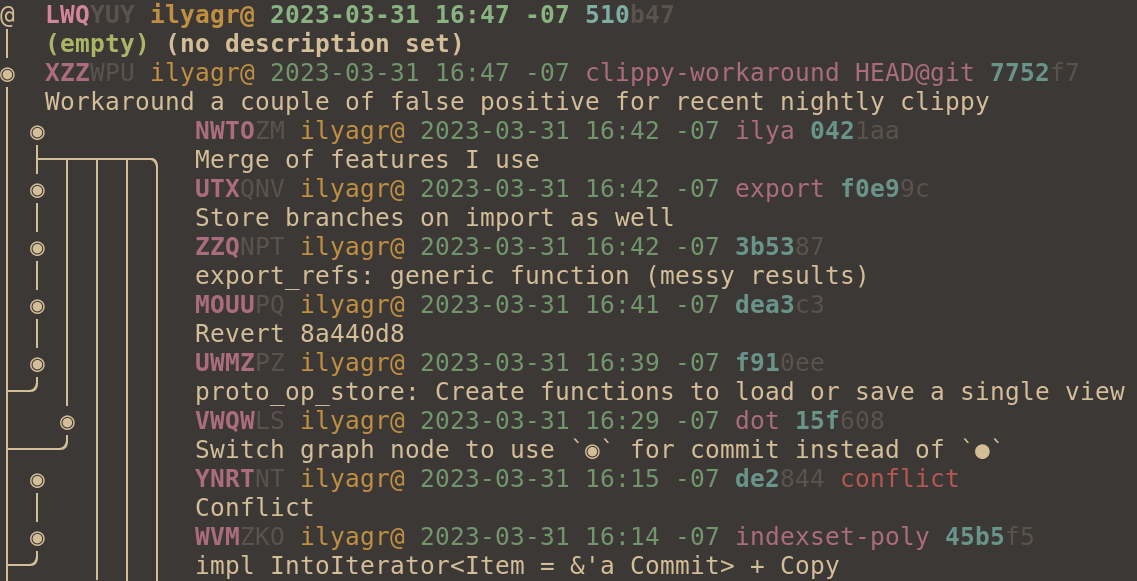
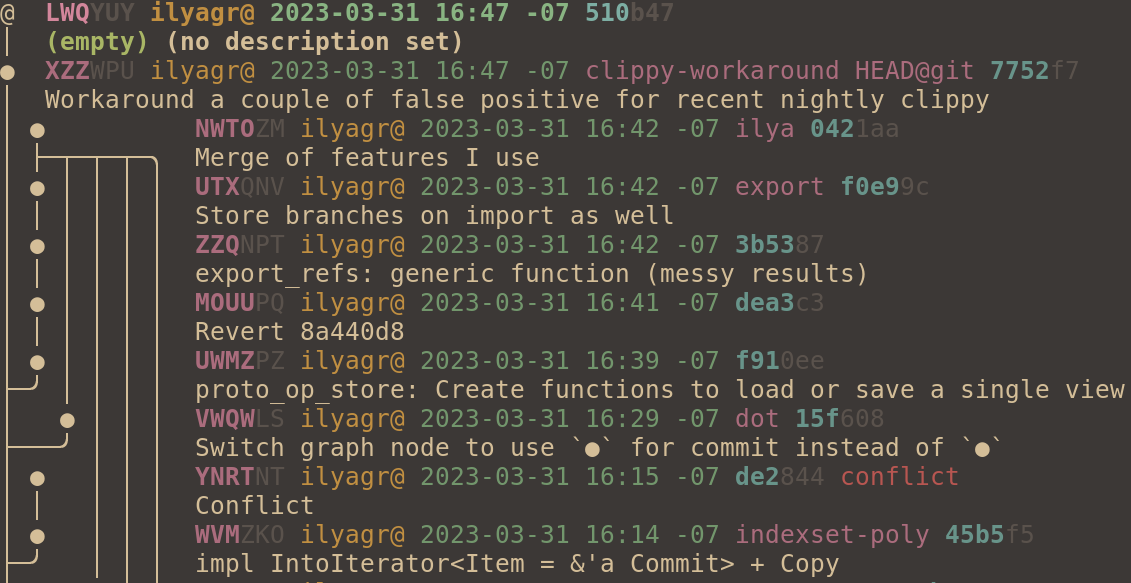
@joyously found `o` confusing because it's a valid change id prefix. I
don't have much preference, but `●` seems fine. The "ascii",
"ascii-large", and "legacy" graph styles still use "o".
I didn't change `@` since it seems useful to have that match the
symbol used on the CLI. I don't think we want to have users do
something like `jj co ◎-`.
Unlike Mercurial, this isn't a template keyword/function, but a config knob.
Exposing graph_width to templater wouldn't be easy, and I don't think it's
better to handle terminal wrapping in template.
I'm not sure if patch content should be wrapped, so this option only applies
to the template output for now.
Closes#1043
This eliminates ambiguous parsing between "func()" and "expr ()".
I chose "++" as template concatenation operator in case we want to add
bit-wise negate operator. It's also easier to find/replace than "~".
Since there's no easy API to snapshot the stale working copy without releasing
the lock, we have to compare the tree ids after reacquiring the lock. We could
instead manually snapshot and rebase the working-copy commit, but that would
require more copy-paste codes.
Closes#1310
The outermost "op-log" label isn't moved to the default template. I think
it belongs to the command's formatter rather than the template.
Old bikeshedding items:
- "current_head", "is_head", or "is_head_op"
=> renamed to "current_operation"
- "templates.op-log" vs "templates.op_log" (the whole template is labeled
as "op-log")
=> renamed to "op_log"
- "template-aliases.'format_operation_duration(time_range)'"
=> renamed to 'format_time_range(time_range)'
We write conflict to the working copy by materializing them as
conflict markers in a file. When the file has been modified (or just
the mtime has changed), we parse the markers to reconstruct the
conflict. For example, let's say we see this conflict marker:
```
<<<<<<<
+++++++
b
%%%%%%%
-a
+c
>>>>>>>
```
Then we will create a hunk with ["a"] as removed and ["b", "c"] as
added.
Now, since commit b84be06c08, when we materialize conflicts, we
minimize the diff part of the marker (the `%%%%%%%` part). The problem
is that that minimization may result in a different order of the
positive conflict terms. That's particularly bad because we do the
minimization per hunk, so we can end up reconstructing an input that
never existed.
This commit fixes the bug by only considering the next add and the one
after that, and emitting either only the first with `%%%%%%%`, or both
of them, with the first one in `++++++++` and the second one in
`%%%%%%%`.
Note that the recent fix to add context to modify/delete conflicts
means that when we parse modified such conflicts, we'll always
consider them resolved, since the expected adds/removes we pass will
not match what's actually in the file. That doesn't seem so bad, and
it's not obvious what the fix should be, so I'll leave that for later.
When we materialize modify/delete conflicts, we currently don't
include any context lines. That's because modify/delete conflicts have
only two sides, so there's no common base to compare to. Hunks that
are unchanged on the "modify" side are therefore not considered
conflicting, and since they they don't contribute new changes, they're
simply skipped (here:
3dfedf5814/lib/src/files.rs (L228-L230)).
It seems more useful to instead pretend that the missing side is an
empty file. That way we'll get a conflict in the entire file.
We can still decide later to make e.g. `jj resolve` prompt the user on
modify/delete conflicts just like `hg resolve` does (or maybe it
actually happens earlier there, I don't remember).
Closes#1244.
It's been about 10 weeks and 730 commits since 0.6.0, compared to
about 7 weeks and 350 commits between 0.5.0 and 0.6.0, so it's time
for a new release. There's been significant user-visible changes and
code-quality improvements. Thanks, everyone!
Supported values are,
- `none` for no author information,
- `full` for both the name and email,
- `name` for just the name,
- `username` for username part of the email,
- (default) `email` (or any other gibberish for that matter) for the full email.
I felt that the config is too narrow to have it's own top-level [diff]
section, and I couldn't think of another good place to have it. I'm
happy to hear other suggestions.
For stock merge-tools, having name -> args indirection makes sense. For
user-specific settings, it's simpler to set command name and arguments
together.
It might be a bit odd that "name with whitespace" can be parsed differently
depending on the existence of merge-tools."name with whitespace".
We have moved from saying "committing the working copy" towards saying
"snapshotting the working copy". More importantly, the option also
means that we don't update the working copy at the end. I went with
the `--ignore-working-copy` name suggested by Ilya. I also updated the
documentation of the option.
This allows us to use "if(description,)" to test empty description. And
I think this change is unavoidable if we want to add support for commit
template.
Git's HEAD ref is similar to other refs and can logically have
conflicts just like the other refs in `git_refs`. As with the other
refs, it can happen if you run concurrent commands importing two
different updates from Git. So let's treat `git_head` the same as
`git_refs` by making it an `Option<RefTarget>`.
I think of it more as style than a format, so using `style` in the
config key makes sense to me.
I didn't bother making upgrades easy by supporting the old name since
this was just released and only a few developers probably have it set.
The name of the [alias] section is inconsistent with other
table-valued sections ([revset-aliases], [colors], [merge-tools]), so
let's rename it. For comparison, `Cargo.toml` also uses plural names
(e.g. `[dependencies]`).
This is an example of labeled output of structured value types. I think
"{name} <{email}>" is a good default formatting, but I should note that
the signature also contains timestamp field.
This makes us sanitize ANSI escape bytes in the output if it goes to
the terminal, even when it's not colored (by us), such as when using
`--color=never`. That means that e.g. `jj cat
tests/test_commit_template.rs` will not be colored, but `jj cat
tests/test_commit_template.rs | cat` will be. Sanitizing output sent
to the terminal might help reduce some security threats based on
hiding content by using ANSI escapes.
We could add a config option for sanitizing the output, but I'm not
sure it'll be useful.
`jj cat` better matches `hg cat` and, of course, `cat`. I apparently
called it `jj print` when I added it in 7a013a59ae because I haven't
found `hg cat` useful for actually concatenating files. That's still
true, and I don't know if we will ever bother to teach `jj cat` to
actually concatenate files, but I think the familiarity of `cat` is
more important.
For reference, Git calls it `git show <rev>:<file>`.
I kept `print` as an alias and added a test for it. I also documented
the test better.
By the way, I've considered adding a command for writing from stdin
directly to a specific commit. If we ever do, it might make sense to
call that command `write` (e.g. `echo foo | jj write -r @-
README.md`). Then it would make sense to add `read` as an alias to
`cat`. I'm not sure that's a good idea, but let's leave that for later
anyway.
The `indexmap` crate is used to make `duplicate`'s output have a sane order,
making it easier to test.
It's also used later to remove duplicate revisions in the `abandon` command.
Fixes https://github.com/martinvonz/jj/issues/1050
Thanks to Martin for suggesting the exact fix.
The tests go into the new tests/test_duplicate_command.rs, which will be
expanded shortly with other tests depending on this bugfix.
The `git.fetch` and `git.push` keys can be used in the configuration file
for the default to use in `jj git fetch` and `jj git push` operations.
By defaut, "origin" is used in both cases.
You may use "abc\\" in .gitignore to ignore a file named "abc\". In this
case, removing training spaces on "abc\\ " must result in "abc\\" as the
trailing space is not escaped, the preceeding backslash being part of
the previous "\\" escaping sequence.
- branches has the signature branches([needle]), meaning the needle is optional (branches() is equivalent to branches("")) and it matches all branches whose name contains needle as a substring
- remote_branches has the signature remote_branches([branch_needle[, remote_needle]]), meaning it can be called with no arguments, or one argument (in which case, it's similar to branches), or two arguments where the first argument matches branch names and the second argument matches remote names (similar to branches, remote_branches(), remote_branches("") and remote_branches("", "") are all equivalent)
If a workspace path is explicitly specified, it must point to the exact
workspace directory. This is the same behavior as 'hg -R'. OTOH, 'git -C'
is the option to chdir, so it makes sense to search .git from that directory.
This also fixes 'jj -R ../..' which would previously look up '../..', '..',
'.', ...
Since per-repo config may contain CLI settings, it must be visible to CLI.
Therefore, UserSettings::with_repo() -> RepoSettings isn't used, and its
implementation is nullified by this commit.
#616
Otherwise the description set by -m would differ from the one set by editor.
This fixes test_describe() which says "make no changes", but previously "\n"
would be added by the second "jj describe".
As you can see, almost all hashes change in CLI tests. This means in-flight
PRs will need to be rebased to update insta snapshots.
Description text could be normalized by CommitBuilder, but the caller would
have to normalize it beforehand to compare with the current description, so
we would need an explicit function anyway. Another idea is to add a newtype
that represents a normalized description, and make CommitBuilder require it.
Commit::description() will return &Description in place of &str to ensure
that commit.description() == raw_str wouldn't compile.
Git CLI provides --cleanup=<mode> option to switch normalization rules, but
I don't think we'll need such feature.
"jj log -p --summary" now shows summary and color-words diff, like
"hg log -p --stat".
Handling of "-p" is tricky. I first considered "-p" would turn on the default
diff output, but I found it would be confusing if "jj log -p --git" showed
both color-words and git diffs. So the default format is inserted only if
no --git nor --color-words is explicitly specified.
The author timestamp is rarely useful (in my experience). The
committer timestamp, on the other hand, can be useful for
understanding when a change was most recently modified. IIRC, I
originally picked the author timestamp to match the email (which is
the author's), but it's probably not confusing to use the author email
and the committer timestamp. I suspect few users will even reflect on
it.
The number of lines in the diff output is unchanged.
This makes diffs a little more readable when the "..." would otherwise hide a
single line of code that helps in understanding the surrounding context lines.
This change mostly rearranges the loop that consumes the diff lines, so it can
buffer up to num_context_lines*2+1 lines instead of just num_context_lines.
There's a bit of extra code to handle times when a "..." replaces the last line
of a diff.
Note that `jj diff --git` is unchanged, and will still output `@@` lines that
replace a single line of context.
This fixes the bug described in the previous commit.
Because we now print the message about failed exports also while
snapshotting, we may end up reporting it twice on one command. I'm not
sure it's worth worrying about that. We can deal with that later if it
turns out to be a common complaint.
When a workspace's working-copy commit is updated from another
workspace, the workspace becomes "stale". That means that the working
copy on disk doesn't represent the commit that the repo's view says it
should. In this state, we currently automatically it to the desired
commit next time the user runs any command in the workspace. That can
be undesirable e.g. if the user had a slow build or test run started
in the working copy. It can also be surprising that a checkout happens
when the user ran a seemingly readonly command like `jj status`.
This patch makes most commands instead error out if the working copy
is stale, and adds a `jj workspace update-stale` to update it. The
user can still run commands with `--no-commit-working-copy` in this
state (doing e.g. `jj --no-commit-working-copy rebase -r @ -d @--` is
another way of getting into the stale-working-copy state, by the way).
It seems like I forgot to update the `jj status` output when I decided
(years ago?) that the changes in a commit should always be compared to
the auto-merged parents. I was very confused before I realized that
`jj status` was showing the diff summary against the first parent. I
suppose the fact that `jj status` lists only one parent should have
been a hint. Thanks to ilyagr@ for finding this odd behavior. This
patch fixes it by making the command list all parents, and changes the
diff summary to be against the auto-merged parents.
As dbarnett@ reported on #9, our default of `less`, combined with our
default of enabling color on TTYs, means that we print ANSI codes to
`less` by default. Unless the user has set e.g. `$LESS=R`, `less` is
going to escape those codes, resulting in garbage like this:
```
@ ESC[1;35mbb39c26a29feESC[0m ESC[1;33m(no email configured)ESC[0m ESC[1;36m2022-12-03....
```
I guess most of us didn't notice because we have something like
`$LESS=FRX` set.
This patch changes our default from `less` to `less -FRX`. Those are
the flags we're using for our internal hg distribution at Google, and
that has seemed quite uncontroversial.
I added a pointer from the changelog to the tracking issue while at
it.
To prevent git's GC from breaking a repo, we already add a git ref to
commits we create in the git backend. However, we don't add refs to
commits we import from git. This fixes that.
Closes#815.
With this patch, we auto-upgrade existing repos that use Thrift format
for the operation log to use Protobuf format. That would only be repos
used with an unreleased version of jj after 0.5.1 (which may be the
majority of repos?).
The upgrade from Thrift is simpler because we now use the same hashing
scheme for the Protobuf-based storage, so the operation and view IDs
remain the same as they were in the Thrift-based storage. We could
simplify the code a bit more as a result, but since this code is
supposed to be short-lived, I didn't bother.
Since the change from the Protobuf format with the old hashing scheme
to a the (same) Protobuf format with the new hashing scheme shouldn't
impact users, I removed the entry we had in the changelog about the
format change.
I thought I had seen our current formatting, i.e. `(#123)`, get
auto-linked by GitHub, but it seems it doesn't. This patch therefore
changes to use markdown links. I copied the style from Cargo (and
Clippy).
The change in hashing scheme should not even be noticeable, except
maybe because the same objects may be saved twice and take extra
space, and may be slower because we compare the contents for equality
instead of short-circuiting when we the hash matches.
This fixes the bugs shown by the tests added in the previous patch by
checking that the git branches we're about to update have not been
updated by git since our last export. If they have, we fail those
branches. The user can then re-import from the git repo and resolve
any conflicts before exporting again.
I had to update the `test_export_import_sequence` to make it
pass. That shows a new bug, which I'll fix next. The problem is that
the exported view doesn't get updated on import, so we would try to
export changes compared to an earlier export, even though we actually
knew (because of the `jj git import`) that the state in git had
changed.
The Protobuf team at Google decided to let us use Protobufs internally
after all. That will make things a little easier for us with the
Google-internal adapations, and the `protobuf` crate is noticeably
faster than the `thrift` crate.
This effectively rolls back commit 5b10c9aa0a. I resolved some
conflicts caused by the rename from `NormalFile` to `File`. I also
kept the changelog entry, but I changed it to say that the hashing
scheme has changed (not the format), but since the hashes are just
used for identity, existing repos should still work.
A new FileType, GitSubmodule is added which is ignored. Files or
directories having this type are not added to the work queue and
are ignored in snapshot. Submodules are not created by jujutsu
when resetting or checking out a tree, they should be currently
managed using git.
Teach Ui's writing functions to write to a pager without touching the
process's file descriptors. This is done by introducing UiOutput::Paged,
which spawns a pager that Ui's functions can write to.
The pager program can be chosen via `ui.pager`. (defaults to Defaults to
$PAGER, and 'less' if that is unset (falling back to 'less' also makes
the tests pass).
Currently, commands are paginated if:
- they have "long" output (as defined by jj developers)
- jj is invoked in a terminal
The next commit will allow pagination to be turned off via a CLI option.
More complex pagination toggling (e.g. showing a pager even if the
output doesn't look like a terminal, using a pager for shorter ouput) is
left for a future PR.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}